| Brutus | −→ | 1 | 2 | 4 | 11 | 31 | 45 | 173 | 174 | |
| Caesar | −→ | 1 | 2 | 4 | 5 | 6 | 16 | 57 | 132 | … |
| Calpurnia | −→ | 2 | 31 | 54 | 101 | |||||
 | ||||||||||
 |  | |||||||||
| dictionary | postings | |||||||||
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Definition 7.2.1 (auch Dokumentenzugriffssystem, engl. Information Retrieval (IR)). Die klassische Volltextsuche liefert (Referenzen auf) Dokumente zurück, welche für eine Kombination von Suchtermen und Suchkriterien (=Anfrage, query) relevant sind. Die Suchterme selbst können beliebige im Text vorkommende Ausdrücke sein – es wird nicht wie bei Bibliothekskatalogen mit geschlossenen Sachbegriffen indiziert.
Hinweis zu den Einheiten des Retrievals
Anstelle von ganzen Dokumenten als Suchresultat kann man auch kleinere Textstellen (engl. passage retrieval ) als Wiedergewinnungseinheit definieren.
Beispiel 7.2.2 (Googles define-Operator).
Gewisse Suchmaschinen unterstützen die Suche nach definitionsartigen Passagen.
Definition 7.2.3 (Volltext-Indexieren). Beim Indexieren einer Dokumentensammlung werden (fast) alle Wörter jedes Dokuments ausgewählt , zu Indextermen normalisiert und im Index abgelegt.
Definition 7.2.4 (Index). Ein Index eines IR-Systems ist eine Daten(infra)struktur, aus der sich für jeden Indexterm effizient bestimmen lässt, in welchen Dokumenten er vorkommt.
Meta-Information zu Dokumenten
IR-System erlauben oft, Einschränkung bezüglich Alter, Sprache, Herkunft etc. von Dokumenten in die Anfrage einzubauen. Solche Informationen müssen für jedes Dokument gespeichert werden.
Beispiel: Vorkommensmatrix in Shakespeare-Stücken
Term-document incidence matrix nach [Manning et al. 2009]
| Anthony | Julius | The | Hamlet | Othello | Macbeth | … | |
| and | Caesar | Tempest | |||||
| Cleopatra | |||||||
| Anthony | 1 | 1 | 0 | 0 | 0 | 1 | |
| Brutus | 1 | 1 | 0 | 1 | 0 | 0 | |
| Caesar | 1 | 1 | 0 | 1 | 1 | 1 | |
| Calpurnia | 0 | 1 | 0 | 0 | 0 | 0 | |
| Cleopatra | 1 | 0 | 0 | 0 | 0 | 0 | |
| mercy | 1 | 0 | 1 | 1 | 1 | 1 | |
| worser | 1 | 0 | 1 | 1 | 1 | 0 | |
| … |
Lesebeispiele
Der Term „Calpurnia“ kommt im Stück Julius Caesar vor.
Der Term „Calpurnia“ kommt im Stück The Tempest nicht vor.
Speicherplatzprobleme der Vorkommensmatrix
Fast alle Tabellenzellen sind 0
Aus Effizienzgründen sollte nur gespeichert werden, in welchen Dokumenten ein Term tatsächlich vorkommt.
Dictionary
Die Menge aller Indexterme (dictionary) sollte im Hauptspeicher Platz finden. Durch Termnormalisierung und Stoppwörter lassen sich ca. 1/3 der Indexterme entfernen. [Manning et al. 2009, 89]
Invertierter Index (inverted index)
| Brutus | −→ | 1 | 2 | 4 | 11 | 31 | 45 | 173 | 174 | |
| Caesar | −→ | 1 | 2 | 4 | 5 | 6 | 16 | 57 | 132 | … |
| Calpurnia | −→ | 2 | 31 | 54 | 101 | |||||
| | ||||||||||
| | | |||||||||
| dictionary | postings | |||||||||
Auswahl der Indexterme
Nach der Tokenisierung werden aus Gründen der Effizienz und/oder Relevanz oft bestimmte Wörter
(noise words) ausgefiltert.
Es gibt auch Suchmaschinen, welche alles indizieren – interessant für CL-Ansätze “WWW als Korpus”.
Eine kleine Stoppwortliste für Englisch ▸▸▸
a about after again ago all almost also always am an and another any anybody anyhow anyone
anything anyway are as at away back be became because been before being between but by came can
cannot come could did do does doing done down each else even ever every everyone everything for
from front get getting go goes going gone got gotten had has have having he her here him his how i if
in into is isn’t it just last least left less let like make many may maybe me mine more most much my
myself never no none not now of off on one onto or our ourselves out over per put putting same saw
see seen shall she should so some somebody someone something stand such sure take than that the
their them then there these they this those through till to too two unless until up upon
us very was we went were what what’s whatever when where whether which while who
whoever whom whose why will with within without won’t would wouldn’t yet you your
Indexterme normalisieren
Die Normalisierung kann keine bis viel Sprachtechnologie enthalten:
 analys
analys
 analys
analys
 analyt
analyt
Stemming mit dem Porter-Stemmer ▸▸▸
Beispiel 7.2.5 (Porter-Stemmer für Englisch).
These analyses seemed especially analytic.
 these
these
 analys
analys
 seem
seem
 especi
especi
 analyt
analyt
 “aufessen”
“aufessen”
 “schwimm”
“unterricht”
“schwimm”
“unterricht”
 “überzeugen”
“überzeugen”
 “Computer”, “Luisa”
“Computer”, “Luisa”  “Louise”
“Louise”
Beispiel: Automatisches Indexieren von OPAC-Daten

Quelle:[Oberhauser und Labner 2003]
| Abbildung 7.8: | Automatisches Indizieren von OPAC-Informationen: Gut |

Quelle:[Oberhauser und Labner 2003]
| Abbildung 7.9: | Automatisches Indizieren von OPAC-Informationen: Schlecht |
IR-System-Architektur [Carstensen et al. 2004, 483]
Frage
Warum hat es zwischen dem Kästchen “Anfrage-Compiler” und “Termextraktion und linguistische Normalisierung” eine Verbindung?
Dokument als Menge von Indextermen
Definition 7.2.6 (engl. bag of words (BOW)). Im IR wird ein Dokument meist als Menge von Indextermen betrachtet.
Definition 7.2.7 (Boolsches Retrievalmodell). Im Boolschen Retrievalmodell werden die einzelnen Suchterme der Anfrage mit den logischen Operatoren “UND”, “ODER” und “NICHT” verknüpft zu einer komplexen Anfrage.
Beispiel 7.2.8 (Logische Operatoren).
Die Anfrage Schuhmacher UND Suzuka UND (NICHT Michael) bedeutet:
Finde alle Dokumente, welche
Probleme des Boolschen Retrievalmodells
Zweiwertigkeit
Wegen der klassischen Zweiwertigkeit , d.h. keine partiellen Treffer, können (bei kleineren Dokumentensammlungen) Null-Treffermengen entstehen.
Bei grossen Dokumentensammlungen wiederum können übergrosse Treffermengen entstehen. Eine gute Reihenfolge der Suchresultate nach Relevanz ist notwendig (erweitertes Boolsches Modell)
Dokument als Indexterm-Menge
Die Dependenzen zwischen den Wörtern lassen sich nicht darstellen. Ein Aufsatztitel wie “A formal specification language for the automatic design of chips by computer” bedeutet dasselbe wie die Wortmenge “automatic, chip, computer, design, formal, language, specification”.
Problem der Mengen-Repräsentation für die Suche
Beispiel 7.2.9 (Dokument mit seine Termmenge).
Dokument: “A formal specification language for the automatic design of chips by computer”
Termmenge: “automatic, chip, computer, design, formal, language, specification”
Beispiel 7.2.10 (Anfragen und ihre Term-Mengen).
Welches Problem haben wir?
Relevanzabschätzung von Indextermen
Um die Relevanz von Indextermen gegenüber Dokumenten, welche sie enthalten, abschätzen zu
können, werden unterschiedlichste Masse angewendet und kombiniert.
Definition 7.2.11 (engl. term frequency (TF)). Die Relevanzhypothese zur Termhäufigkeit besagt: Je häufiger ein Indexterm in einem Dokument erscheint, umso relevanter ist das Dokument für den Term.
Definition 7.2.12 (engl. inverse document frequency (IDF)). Die Relevanzhypothese zur inversen Dokumenthäufigkeit besagt: Je seltener ein Indexterm eines Dokuments d in anderen Dokumenten der Gesamtkollektion D erscheint, umso relevanter ist Dokument d für den Indexterm.
Überlegungen zu Stoppwörter, TF und IDF
Fragen
Die TF/IDF-Formel nach [Salton 1988]
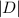 .
.
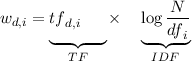
Fragen
Welche Werte kann tfd,i und 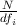 maximal/minimal annehmen? Was macht log?
maximal/minimal annehmen? Was macht log?
Definition 7.2.13 (Vektorraummodell (vector space model)). Ein einfaches Vektorraummodell entsteht, wenn in der Vorkommensmatrix anstelle der 1 das Gewicht (z.B. klassisch TF/IDF) eingetragen wird. Jede Zeile in Vorkommensmatrix ist ein Vektor (Folge von Werten).
Beispiel 7.2.14 (Interaktive Demo zu Vektorraummodell).
http://kt2.exp.sis.pitt.edu:8080/VectorModel/main.html
Idee: Relevanz als Vektorähnlichkeit
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
