GPSG steht für Generalized Phrase Structure Grammar. GPSG wurde zu Beginn der 80er Jahre entwickelt. Als Standardreferenz und umfassendste Darstellung gilt [Gazdar et al. 85]. Ich stütze mich ausserdem vor allem auf [Bennett 95].
Eine Grammatik nach GPSG besteht aus:
Auf die dadurch erzeugten Strukturen wirken die
Die Trennung von Dominanz- und Präzedenzinformation wurde bereits in Vorlesung1 vorgestellt. Beachte, dass die folgenden zwei ID-Regeln vollkommen gleichbedeutend sind.
S --> V2, N2 S --> N2, V2
Weiterhin ist zu beachten, dass eine LP-Regel immer für alle ID-Regeln gilt. Es gibt keine Möglichkeit, eine LP-Regel nur auf eine spezielle ID-Regel zu beziehen.
Bei den ID-Regeln wird unterschieden zwischen:
Die Trennung zwischen ID- und LP-Regeln erlaubt es,
Der zweite Punkt ist z.B. bei der Beschreibung des Deutschen ein Vorteil, wo wir die variable Ordnung im sog. Mittelfeld mit einer ID-Regel und zwei LP-Regeln erfassen können.
VP --> V[fin], NP[nom], NP[dat], NP[akk], (V[inf]). V[fin] < NP. NP < V[inf].
Damit können wir die folgenden VPs beschreiben:
Gestern [hat Peter dem Mann den Ball gegeben]. Gestern [hat dem Mann Peter den Ball gegeben]. Gestern [hat Peter den Ball dem Mann gegeben]. Gestern [hat den Ball Peter dem Mann gegeben]. Gestern [hat den Ball dem Mann Peter gegeben]. Gestern [hat dem Mann den Ball Peter gegeben].
Frage: Kann man mit ID/LP-Grammatiken alle Strukturen beschreiben, die man auch mit PS-Grammatiken beschreiben kann? In anderen Worten: Ist jede PS-Grammatik übersetzbar in eine gleichwertige ID/LP-Grammatik?
Antwort: Es gibt PS-Grammatiken, die man nicht in eine gleichwertige ID/LP-Grammatik übersetzen kann.
(G1) S --> NP VP NP --> Art NG VP --> V (NP) (PP) (S) PP --> P NP NG --> N (S) (PP)
Die PS-Grammatik in (G1) kann nicht in eine gleichwertige ID/LP-Grammatik übersetzt werden, da (PP) vor (S) steht, wenn der Mutterknoten VP ist, aber die Reihenfolge umgekehrt ist, wenn der Mutterknoten NG ist. Es gibt jedoch eine ID/LP-Grammatik, die dieses Problem behebt:
(G2) S --> NP, VP NP --> Art, NG VP --> V, (NP), (PP), (Z) PP --> P, NP NG --> N, (S), (PP) Z --> S NP < VP Art < NG V < X N < X NP < PP PP < Z S < PP
Die ID/LP-Grammatik in (G2) akzeptiert die gleiche Sprache wie die PS-Grammatik in (G1), aber sie fügt ein Hilfssymbol Z ein, um die Reihenfolgebeschränkungen zu erfüllen. Wenn dieses Hilfssymbol linguistisch nicht motiviert werden kann, sollte es nicht in der Grammatik vorkommen. Durch dieses Hilfssymbol wird manchen Sätzen eine andere Struktur zugewiesen als in (G1).
Es gilt: Erzeugen zwei Grammatiken die gleichen Sätze, aber mit (teilweise) unterschiedlichen Strukturen, so sind sie schwach äquivalent. Erzeugen sie die gleichen Sätze mit gleichen Strukturen, so sind sie stark äquivalent.
Eine PS-Grammatik, die in eine stark äquivalente ID/LP-Grammatik umgeformt werden kann, muss die sog. ECPO-Eigenschaft haben. ECPO steht für Exhaustive Constant Partial Ordering. Die Reihenfolge heisst konstant, da jede Reihenfolge für alle Regeln gelten muss.
Konstituenten in GPSG sind Merkmalstrukturen. Die Liste im Anhang von [Gazdar et al. 85] bietet eine Übersicht über die verwendeten Merkmale (engl. features) mit ihren jeweiligen Wertebereichen. Die Merkmale werden in (nicht-disjunkte) Teilmengen aufgeteilt:
Man beachte, dass einige Merkmale idiosynkratische Bezeichnungen erhalten haben: das Merkmal 'Numerus' heisst hier PLU mit dem Wertebereich {+,-}. Weiterhin beachte man, dass die Merkmale N, V und BAR dazu dienen, die grundlegenden Kategorien A, N, P, V auf den verschiedenen Ebenen zu repräsentieren, wie das in Vorlesung 1 unter 'Verallgemeinerung über Kategorien' angesprochen worden ist.
In der GPSG-Literatur finden sich folgende Notationen für Merkmal-Wert Paare:
[CASE ACC] [CASE=ACC] [ACC] wenn zugehöriges Merkmal eindeutig [+ PLU] wenn Merkmal binärwertig [VFORM] wenn Merkmal mit beliebigem Wert ~[VFORM] wenn Merkmal nicht auftreten darf
Das Bar-Level wird entweder nicht geschrieben (vor allem bei Bar-Level 0) oder als einfache Ziffer oder als Exponent notiert.
VP = V2 = V2 = {[N -], [V +], [BAR 2]} = V2
V' = V1 = V1 = {[N -], [V +], [BAR 1]}
V = V0 = V0 = {[N -], [V +], [BAR 0]}
Insbesondere darf die Angabe für das Bar-Level nicht mit der Angabe der Subkat-Klasse verwechselt werden.
V2 ist V mit BAR-Level 2 V[2] ist V mit Subkat-Klasse 2
Aufgrund von Ähnlichkeiten zwischen subjektlosen (VP) und subjekt-enthaltenden (S) Infinitivkonstruktionen, kam man zu dem Schluss, dass zwischen VP und S kein grundlegender Unterschied besteht. Das wird untermauert durch die Beobachtung, dass das Verb die zentrale Rolle im Satz spielt, so dass man den Satz als Projektion einer VP auffassen kann. Deshalb gilt in GPSG:
S = V2[Subj +] = {[N-], [V+], [Bar 2], [Subj +]}
VP = V2[Subj -] = {[N-], [V+], [Bar 2], [Subj -]}Ein Nebensatz wird vom Matrixsatz unterschieden durch das Merkmal COMP. Damit gilt als generelle Regel zur Einführung eines Nebensatzes:
(51) V2[Subj +, Comp] --> Comp, V2[Subj +, ~Comp] (vorläufige Version)
In GPSG wird Subkategorisierung über das Merkmal Subcat geregelt, das für jeden Valenzrahmen einen eindeutigen Zahlenwert erhält.
(1) V2 --> V[Subcat 1] (die) (2) V2 --> V[Subcat 2], NP (love) (3) V2 --> V[Subcat 3], NP, PP[Pform to] (give) (4) V2 --> V[Subcat 4], NP, PP[Pform for] (buy)
Beachte: Subkat-Werte werden auch für Adjektive, Präpositionen und Nomen vergeben.
Durch die Vergabe des Subkat-Merkmals an die lexikalischen Heads können diese von den anderen Kategorien unterschieden werden. Für das Englische wird entsprechend die folgende LP-Regel postuliert, die bewirkt, das ein lexikalischer Head vor allen Geschwisterkategorien steht:
[Subcat] < ~[Subcat]
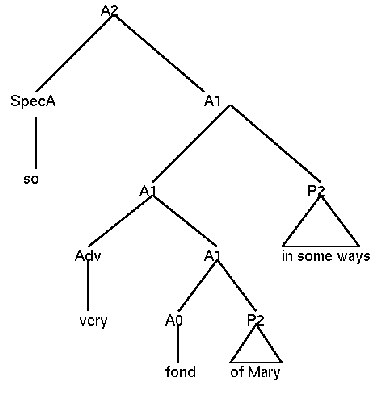
Die Regeln für APs müssen die folgenden Beispiele beschreiben können:
similar to his brother fond of his mother very happy so tall too tall in some respects
Das geschieht mit den folgenden Regeln:
(23) A2 --> (SPECA), A1
A1 --> Adv, A1
A1 --> P2, A1
(25) A1 --> A0[Subcat 25], P2[Pform to] (similar)
A1 --> A0[Subcat n], P2[Pform of] (fond)
SPECA < [Bar 1]
Adv < A1 < P2
Bei der Aufstellung von Regeln muss die Unifikation von Merkmalen immer mit bedacht werden. So gilt z.B., dass ein finiter Satz eine finite VP hat, die wiederum ein finites Verb enthält. Um diese Übereinstimmung von Merkmalen nicht bei jeder Regel explizit aufführen zu müssen, umfasst GPSG Prinzipien, die den Transport von Merkmalen im Syntaxbaum beschreiben. So sagt das Head Feature Principle (manchmal auch Head Feature Convention) :
Mutterknoten und Headtochter müssen in allen Head-Merkmalen übereinstimmen, ausser wenn die Merkmale mit explizitem Wert vorgegeben sind.
Um eindeutig festzulegen, welche Kategorie der Head einer Regel ist, wird diese auch als 'H' notiert.
(2) VP --> H0[Subcat 2], NP (love)
Durch das HFP wird die Information der Merkmale N, V, Bar auf den Head übertragen (genauer: mit dem Head abgeglichen, da es sich um einen Vorgang der Unifikation über Merkmalstrukturen handelt, der per definitionem richtungsneutral ist.)
Die Einführung von Heads erlaubt auch die folgende Aussage:
Jede ID-Regel enthält einen Head.
Die Prinzipien der Merkmalinstanziierung in GPSG beschreiben die Merkmale innerhalb einer Konstituente.
FCRs beschränken die Merkmale, die in einer Merkmalstruktur (d.h. einer Konstituente) zusammen auftreten können. Eine Kategorie, die alle FCRs erfüllt, heisst legale Kategorie. Einige Beispiele für FCRs:
[VFORM] ==> [+V, -N]
Eine Merkmalstruktur, die das Merkmal VFORM enthält (mit irgendeinem Wert), muss auch die Merkmale [+V, -N] enthalten, d.h. muss eine verbale Kategorie sein. Analoge Regeln gibt es für NFORM und PFORM.
[+SUBJ] ==> [+V, -N, Bar 2]
Das Merkmal-Wert Paar [+SUBJ] darf nur bei phrasalen Kategorien auftreten.
[COMP] <==> [+SUBJ]
Nur satzartige Kategorien haben einen Complementizer (und dürfen deshalb das Merkmal COMP tragen) und umgekehrt. Man beachte den Doppelpfeil, der für die zweiseitige Implikation steht.
[Bar 0] <==> [Subcat] & [N] & [V] [Bar 1] ==> ~[Subcat] [Bar 2] ==> ~[Subcat]
... beschreibt die Verteilung des Subcat-Merkmals. Damit wird festgelegt, dass nur lexikalische Kategorien dieses Merkmal haben können und müssen. Die Erweiterung um [N] & [V] ist erforderlich, da Subcat auch bei einigen Kategorien markiert wird, die keinen Wert für Bar haben.
[Past] ==> [Fin]
Wenn eine Verbform als Past tense markiert ist, so muss es sich um ein finites Verb handeln (im Englischen gibt es keinen Infinitiv im Past tense).
FSDs definieren Vorbelegungswerte für Kategorien. Im Gegensatz zu FCR können die Vorbelegungen von anderen Mechanismen einer GPSG (ID-Regel, FCR, HFP) überschrieben werden.
[+N, -V, Bar 2] <==> [Acc]
... besagt, dass eine phrasale Kategorie default-mässig den Kasuswert Acc erhält. Im Gegensatz dazu wird der Nominativ vom finiten Verb zugeordnet.
~[Nom]
... sorgt dafür, dass der Kasuswert Nom nur explizit vergeben wird.
FSDs sind bzgl. der Unifikation von Merkmalstrukturen umstritten (vgl. Vorlesung 3: Default-Werte). Man überlege sich, was passieren muss, wenn eine FSD angewendet wurde, die das Merkmal-Wert Paar [M1 +] einführt, auf das eine FCR [M1 +] ==> [M2 -] angewendet wird, und wenn schliesslich eine Situation eintritt, wo die FSD durch z.B. das HFP in [M1 -] überschrieben wird.
Zur Einführung eines Complementizers haben wir bereits kennengelernt:
(51) V2[Subj +, Comp] --> Comp, V2[Subj +, ~Comp] (vorläufige Version)
Das Merkmal Comp legt fest, welcher Complementizer gefordert ist. Davon abhängig wird über FCR die Form des Nebensatzes bestimmt:
[Comp that] ==> [Vform Fin] [Comp for] ==> [Vform Inf]
Der Wertebereich von Subcat umfasst neben Zahlenwerten auch die Complementizer (und Konjunktionen). Wir müssen sicherstellen, dass die Kategorien V2 und Comp bzgl. des Complementizers übereinstimmen. Deshalb:
(51) V2[Comp X] --> Comp[Subcat X], H[Comp Nil]
mit X aus {that, for, whether, if} (endgültige Version)
Haben wir jetzt einen Satz wie
I believe that John has left
und die ID-Regel (40)
(40) V2 --> H[40], V2[Subj +, Vform Fin]
so erhalten wir den folgenden Baum:
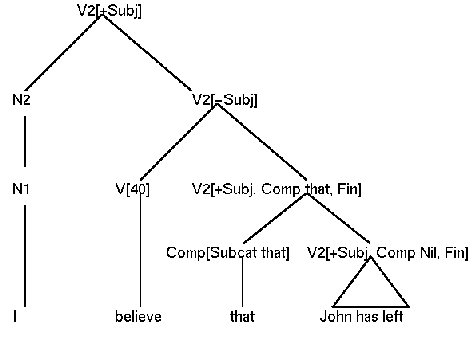
Beachte: ID-Regel (40) kann auch zur Beschreibung des Satzes (ohne Complementizer)
I believe John has left
eingesetzt werden. Comp erhält dann den Wert Nil. Regel (51) wird nicht benötigt.
Für Infinitivkonstruktionen ohne to wie in
Bob made John wash the dishes.
genügt die folgende Regel (Bse steht für base-form, Grundform)
V2 --> H[n], N2, V2[Vform Bse]
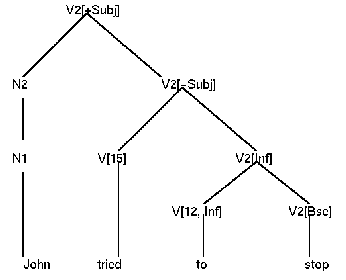
Für Infinitivkonstruktionen mit to wie in
John prefers to wipe up. John persuaded Bob to help him. Jim wishes to leave.
muss es spezielle Regeln geben, die das Auftreten von to regeln. In GPSG wird to als nicht-finites Hilfsverb betrachtet, da es wie andere Hilfs- und Modalverben unmittelbar vor ein infinites Verb treten kann. Nimmt man also
(12) V2[Vform Inf, Aux +] --> H[12], V2[Vform Bse] (to) (15) V2 --> H[15], V2[Vform Inf] (try)
so kann man die folgende Struktur herleiten:
Nominalphrasen werden im GPSG-Standardwerk ([Gazdar et al. 85]) nur marginal behandelt. Es werden einige ID-Regeln für die Subkategorisierung von Nomen (Nr. 30-37) und drei nicht-lexikalische ID-Regeln angegeben. Zu bemerken ist, dass die Reihenfolge der P2s in Regel (31) nicht festgelegt ist, so dass die beiden folgenden Sätze möglich sind.
John regretted his argument [with Bob] [about politics]. John regretted his argument [about politics] [with Bob].
Da bei [Gazdar et al. 85] Angaben über die innere Struktur von N2s fehlen, schlägt [Bennett 95] ergänzend folgende Regeln vor:
N2[Pro -] --> SpecN, H[Bar 1] N2[Pro +] --> H[Bar 1] N1 --> H, P2 N1 --> A2, H Spec < [Bar1] A2 < N1 < P2
Probleme bietet dabei die Stellung der Adjektive innerhalb der N2. So gibt es im Englischen einige Adjektive, die nachgestellt werden können bzw. müssen.
the jewel stolen the people involved all those people present * all those present people * a man proud
Bennett schlägt vor, die betreffenden Adjektive im Lexikon mit einem speziellen Merkmal Post+/- auszustatten, das die Positionierung regelt.
Das Merkmal Pro wird für die Unterscheidung zwischen Personalpronomen und vollen N2s verwedet. Personalpronomen nehmen keine Komplemente, aber sie können Adjektive oder Relativsätze als Attribute erhalten.
poor me lucky me I who have nothing
Weiterhin schlägt Bennett vor, das Merkmal Case als Head-Merkmal zu behandeln, da die Kasus-Information von N2 über N1 zu N0 vererbt werden muss.
Hilfs- und Modalverben gelten in GPSG als Unterklasse der Verben und werden von diesen durch das Merkmal Aux+/- unterschieden. Wie sieht also die Struktur der folgenden Sätze aus? (Passiv wird später behandelt.)
Jim has written a letter. Jim is writing a letter. Jim may write a letter. Jim may have written a letter. Jim may have been writing a letter.
Über die Weglass- und Koordinationsprobe stellt man fest, dass der nicht-auxiliare Verbteil zusammen mit den Komplementen eine Konstituente bildet.
Jim may [write a letter] or [send a postcard]. Is Jim allowed to borrow this book. He may [borrow this book].
Man nimmt deshalb in GPSG die folgende Schachtelung an:
Jim [has [been [writing a letter]]]. Jim [may [have [been [writing a letter]]]].
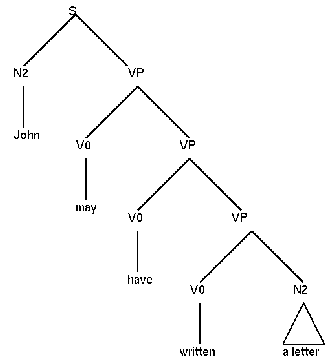
Dazu benötigen wir die folgenden Regeln:
V2[+Aux] --> H[n], V2[Vform Bse] (can, may, should) V2[+Aux] --> H[n], V2[Vform Psp] (have) V2[+Aux] --> H[n], V2[Vform Prp] (be)
Adverbien werden in GPSG als Unterklasse der Adjektive behandelt und von diesen durch das Head-Merkmal Adv+/- unterschieden. Genau wie Adjektive können sie somit auch Phrasen (AdvP) bilden. Im Unterschied zu Adjektiven nehmen Adverbien normalerweise keine Komplemente.
John is fearful of the dark. John entered the room fearfully (*of the dark).
Ausnahmen:
John reached his conclusion independently of Fred. Jim plays similarly to Alan.
Man benötigt also u.a. folgende ID-Regeln für Adverb-Phrasen:
A1[+Adv] --> H[n] (fearfully) A1[+Adv] --> H[n], P2[Pform of] (independently)
Die Beschreibung der Verteilung von AdvP in einem Satz ist schwierig. Es gibt einerseits eine kleine Anzahl von Verben, die ein AdvP als Komplement fordern.
Jack worded the letter carefully. * Jack worded the letter. Jack behaved badly to Kay. * Jack behaved to Kay.
Das kann mit einer normalen VP-Regel erfasst werden (wobei die Festlegung der Reihenfolge problematisch ist):
V2 --> H[n], N2, AdvP (to word)
Darüberhinaus können Adverbien in Klassen unterteilt werden:
Probably the enemy destroyed the city. The enemy destroyed the city, probably. The enemy probably destroyed the city.
* Intentionally the enemy destroyed the village. The enemy intentionally destroyed the village.
Dazu die folgenden Regeln: (man beachte, dass mit V2 sowohl Satz als auch VP gemeint sind).
V2[+Subj] --> H, AdvP[AdvType S] V2[-Subj] --> H, AdvP
GPSG arbeitet mit
Die grundlegenden Kategorien in GPSG sind:
Dazu kommen: