Quelle: [Rinaldi et al. 2006]
[ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Relation-Mining: Text-Mining für Beziehungsentdeckung
Idee des syntax-basierten Relation-Mining
Beispiel 8.3.1 (Unser Ontogene-Projekt: Beziehung zwischen Genen und Proteinen).
Erschliessen von beteiligten Grössen aufgrund vorgegebener Relationen (“activation”) in
biomedizinischen Aufsätzen. Oder Erschliessen von Relationen, welche für beteiligte Grössen
(“NF-kappa B”) belegt sind.
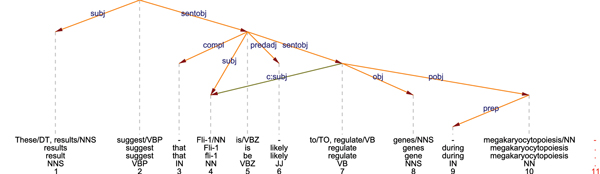
Beispiel: Dependenzanalyse als Grundgerüst
Quelle: [Rinaldi et al. 2006]
Syntaktisch-lexikalische Suchmuster
Die Formulierungen “A regulates B”, “B is regulated by A”, “the regulation of B by A” werden normalisiert. Passiv-Suchmuster: [dep(subj, Verb, OBJ), dep(pobj, Verb, SUB), dep(prep, SUB, By), pos(Verb, ’VBN’), lemma(By, [’by’, ’through’, ’via’])]
Syntaxbasiertes Relation-Mining bei http://www.powerset.com
Syntax-basiertes Web-IR
Die innovative Suchmaschine (gegründet Computerlinguistik-Pionieren) versucht, syntaktische Analyseresultate für IR im grossen Stil fruchtbar zu machen.
Factz von Powerset
Die Faktendatenbank, die als Indexat entsteht, besteht aus einfachen Relationen: Subjekt, Relationstyp, Objekt. Firma wurde von Microsoft aufgekauft, leider keine Demo mehr möglich...