Tag-Ambiguität im Englischen
[ Weiter ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Definition 6.1.1 (Wortarten-Tagger). Ein Wortarten-Tagger (engl. Part-of-Speech Tagger, kurz POS-Tagger) ist ein Programm, das für jedes Token eines Korpus die Wortart bestimmt, indem es ein Klassifikationskürzel als Tag zuordnet.
Beispiel 6.1.2 (Zeilenformat mit Schrägstrich).
Sonderrechte/NN für/APPR Minoritätenkollektive/NN widersprechen/VVFIN
N-Best-Tagging
Tagger, welche die Wortarten mit einer Wahrscheinlichkeit versehen zurückliefern, können für n-best-Tagging verwendet werden.
Definition 6.1.3 (Tag-Set). Ein Tag-Set (Menge der Tags) kodiert typischerweise nebst Wortarteninformation noch semantische, syntaktische oder morphologische Information. Die Grösse eines Tag-Sets kann stark variieren.
| Tag-Set | Grösse | Beispiel | Bedeutung |
| Brown | 87 (179) | she/PPS | Pronoun, personal, subject, 3SG |
| Penn | 45 | she/PRP | Pronoun (personal or reflexive) |
| CLAWS c5 | 62 | she/PNP | Pronoun personal |
| London-Lund | 197 | she’s/RA*VB+3 | pronoun, personal, nominative + verb "to be", present tense, 3rd person singular |
| Tabelle 6.1: | Übersicht: Tag-Sets für Englisch |
Penn-Treebank-Tag-Set (PTTS)
Das wichtigste Tag-Set für Englisch ist eine vereinfachte Version des Brown-Tag-Sets, welches ab den 60-er Jahren in Amerika im Zusammenhang mit dem Brown-Korpus entstanden ist.
Anforderungen an ein Programm für Tagging
Positive Eigenschaften eines Taggers nach [Cutting et al. 1992, 133]:
Wortformen mit mehreren möglichen Tags
Mehrdeutigkeit
Im Brown-Corpus sind 11% aller Wortformen ambig. Das entspricht jedoch 40% der Token.
Tag-Ambiguität im Englischen
Baseline
Nimm für jedes Wort das Tag, mit dem es am häufigsten vorkommt. Ergibt ca. 90% richtige Entscheidungen.
Optimierungspotential
Berücksichtige den linken Kontext (Tags und/oder Wörter) und ev. den rechten Kontext (Wörter), um die Baseline-Entscheidung umzustossen.
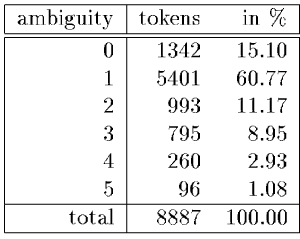
Mehrdeutigkeit bei deutschen Wörtern
Mehrdeutigkeit in einem deutschen Testkorpus (STTS)
Dem Tagger unbekannte Wortformen haben die Ambiguitätsrate 0.
Unbekannte Wörter
Kein Tagger-Lexikon kann vollständig sein (Eigennamen, Komposita, Zahlausdrücke). Wie kann ein
Tagger sinnvolle Vorschläge machen?
Beispiel 6.1.5 (Morphologische Heuristiken für Englisch).
Nutzen und Anwendung des POS-Tagging
POS-Tagging hat sich als eine eigenständige sprachtechnologische Anwendung
erwiesen, welche effizient und zuverlässig durchgeführt werden kann, und für verschiedenste Zwecke
nützlich ist: Lemmatisierung, Lexikographie, Sprachsynthese, Spracherkennung, Dokumentensuche,
Bedeutungsdesambiguierung usw.
Beispiel 6.1.6 (Sprachsynthese/Bedeutungsdesambiguierung).
Der Apostroph in der phonetischen Umschreibung steht vor der hauptbetonten Silbe.
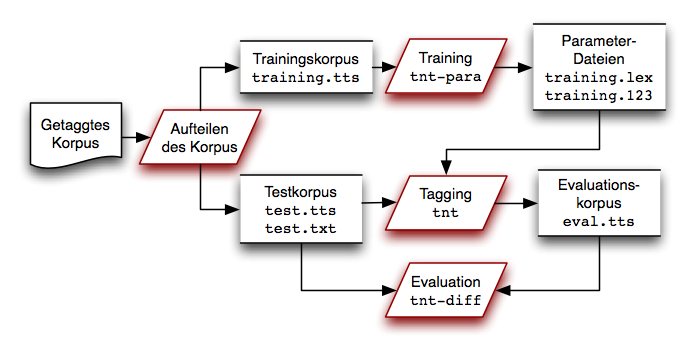
Fallstudie TnT-Tagger: Übersicht
Fallstudie TnT-Tagger: Anpassbarkeit konkret
Man nehme …[Clematide 2007]
[ Weiter ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]