5.4
Multilingualität
Multilinguale Dokumente und Systeme
Herausforderung Multilingualität
- Multilinguale Dokumente oder Systeme erfordern Sprachidentifikation
- Bereits auf Tokensierungsstufe sind sprachspezifische Ressourcen (Abkürzungslexika) und
Regeln notwendig
- Sprachidentifikation ist neben der Identifikation der Zeichenkodierung eines Textes das
Fundament, auf dem alle Textanalyse aufbaut.
- Traditionelles linguistisches Wissen ist für Sprachidentifikation nicht geeignet.
- „Primitive“ Verfahren, welche auf Häufigkeiten von Buchstabenkombinationen aufbauen,
funktionieren gut.
Ansatz von [Cavnar und Trenkle 1994]
- Sammle häufigste Zeichenkombinationen (2-5 Zeichen, d.h. N-Gramme) der verschiedenen
Sprachen über Trainingsdaten.
- Berechne für jede Sprache die Reihenfolge der häufigsten Kombinationen
(N-Gramm-Profil).
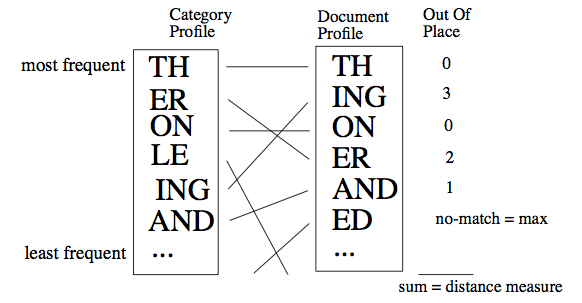
- Berechne für ein unbekanntes Dokument D sein N-Gramm-Profil.
- Berechne den Profilabstand zwischen D und jedem Sprachprofil als Summe des
Rangunterschieds von jedem N-Gramm.
- Wähle für D die Sprache mit dem kleinsten Profilabstand.
N-Gramm-Profile und Profilabstand