|
|
[ Weiter ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Sprachsynthesesysteme ▸▸▸
Definition 9.1.1 (Text-To-Speech System, TTS). Ein Sprachsynthesesystem erzeugt aus einer Zeichenkette (Text) ein akustisches Signal.
Die Spracherzeugung setzt eine mehr oder weniger tiefe linguistische Textanalyse voraus.
Beispiel 9.1.2 (Ein deutscher Stolpersatz).
“Dr. A. Smithe von der NATO (und nicht vom CIA) versorgt z.B. - meines Wissens nach - die Heroin
seit dem 15.3.00 tgl. mit 13,84 Gramm Heroin zu 1,04 DM das Gramm.”
Qualitätsmerkmale für Sprachsynthese
Weiteres
Unterschiedliche Benutzer haben unterschiedliche Bedürfnisse. Blinde Personen schätzen es, wenn das Sprechtempo stark erhöht werden kann.
Einsatzmöglichkeiten von Sprachsynthese
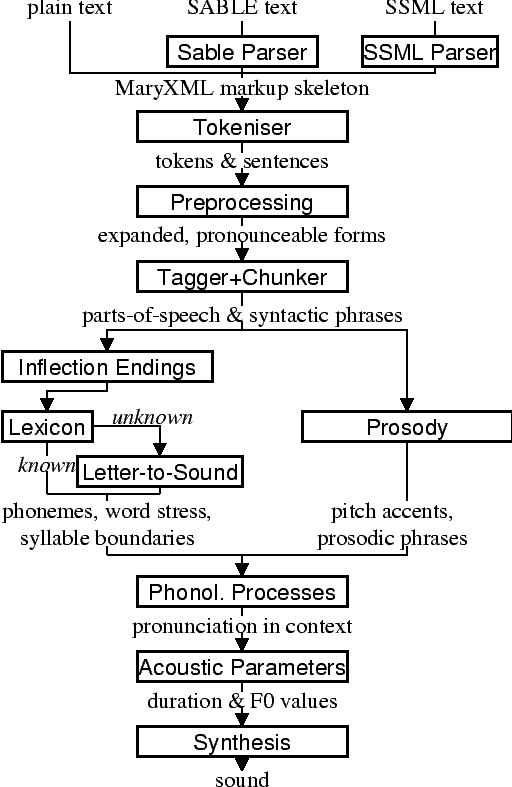
Typische Architektur von TTS
Vom der Zeichenkette zum Laut
Beispiel-Architektur von MARY TTS
Aussprache von Ziffern und Abkürzungen
Die Aussprache von Ziffernotationen variiert vielfältig innerhalb einer Sprache und zwischen
Kulturräumen [LIBERMAN und CHURCH 1992].
Beispiel 9.1.3 (Varianten im Deutschen).
Frage
Welche Aussprachen sind für welche Grössen verbreitet?
Probleme bei Abkürzungen
Welche Schwierigkeiten stellt die Aussprache von Abkürzungen?
Prosodie
Um Satzintonation (Prosodie) korrekt wiederzugeben, braucht es teilweise detaillierte linguistische
Analysen.
Beispiel 9.1.4 (Satzintonation und -rhythmus).
The rear aggregate pumps …
Beispiel 9.1.5 (Satzbetonung und Pausen).
Was ist Prosodie auf Satzebene? [BADER 2006]
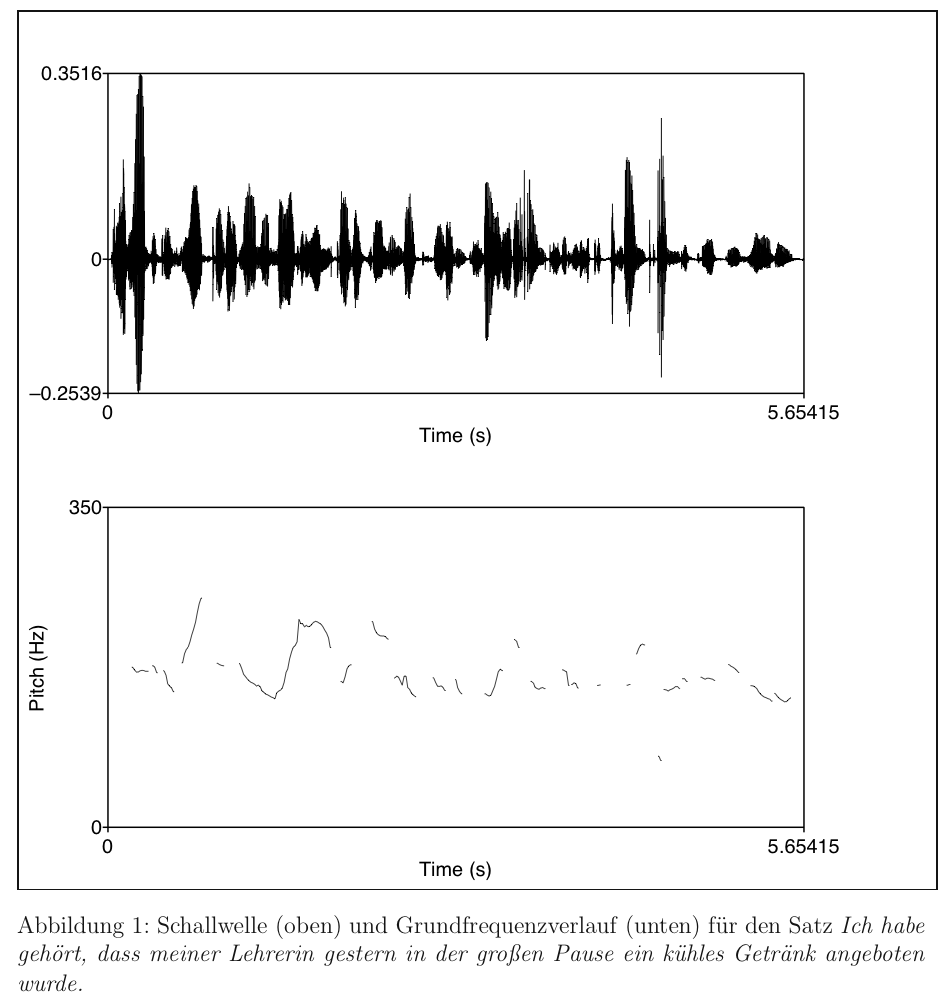
Pausen und Satzbetonung sind an der Amplitude der Schallwellen ablesbar. Der Grundfrequenzverlauf
(oft mit f0 bezeichnet) gibt die relativen Tonhöhenunterschiede in der gesprochenen Sprache wieder.
Ein frei verfügbares Tool, um die verschiedenen akustischen Aspekte der Sprache auf dem Computer zu analysieren, ist unter http://www.praat.org zu finden.
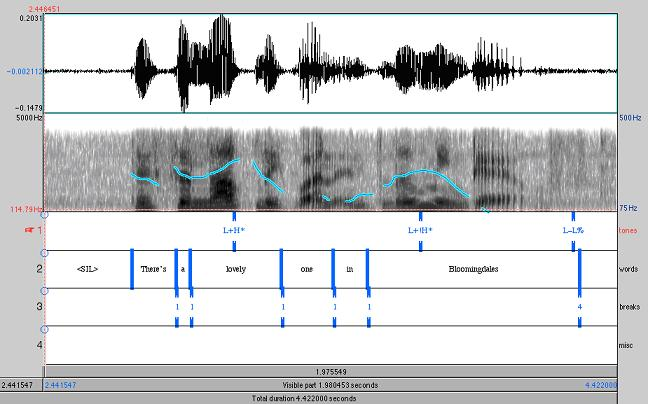
Prosodie: ToBI-Modell (Tones and Break Indices)
Beispiel: Prosodie [SIMMONS 2006b]
|
|
Phonetische Analyse
Wie werden die einzelnen Laute eines Wortes in Isolation repräsentiert?
Definition 9.1.6 (Pronunciation Dictionary). Ein elektronisches Aussprachewörterbuch enthält für (flektierte) Wortformen eine Repräsentation in einer Lautschrift.
Z.B. in Form des International Phonetic Alphabet (IPA) http://www.arts.gla.ac.uk/IPA, bzw. einer auf Computern einfacher verwendbareren Kodierung davon.
Beispiel 9.1.7 (Formate elektronischer Aussprachewörterbücher nach [JURAFSKY und MARTIN 2000]).
Phonetische Lautschrift (SAMPA German)
Eine in ASCII kodierte Notationsvariante für IPA-Symbole.
Frage
Wie kann man das Wort “jenseits” schreiben?
Diphone und Halbphoneme
Die Verwendung der klassischen linguistischen Einheit Phonem (35-50 pro Sprache) für
Sprachgenerierung ergibt keine guten Systeme.
Wie lassen sich natürlichere und fliessende Übergänge der Laute erzeugen?
Definition 9.1.8 (Diphone ▸▸▸). Ein Diphon geht von der Mitte eines Phonems zur Mitte des nächsten Phonems. Für Deutsch kommt man etwa auf 2’500 existierende Diphone, für Spanisch auf 800.
In der Phonemmitte ist das menschliche Gehör weniger empfindlich auf Unebenheiten.
Beispiel 9.1.9 (Stimmen klonen mit Halbphonemen ▸▸▸).
AT&T Natural Voices konnte im Jahr 2001 aus ca. 40h Stimmaufnahmen eine sehr natürliche
Kunststimme extrahieren. Dazu wurden u.a. die verschiedensten Sprechvarianten von Phonemen
aufgenommen und jeweils in der Mitte halbiert.
Phonologische Analyse
Welche Gesetzmässigkeiten der gegenseitigen Beeinflussung von Lauten in ihrem (aus-)sprachlichen
Kontext gelten?
Definition 9.1.10 (Phonological Rules). Phonologische Regeln spezifizieren die Umstände, unter denen phonologische Alternationen statt finden.
Die Zwei-Ebenen-Morphologie bietet eine praktische Modellierung und Implementation dafür an.
Beispiel 9.1.11 (Phonologische Alternationen).
Das Plural-s wird im Englischen je nach Umgebung ganz unterschiedlich ausgesprochen: “peaches”,
“pigs”, “cats”.
Teilweise lassen sich solche Effekte durch maschinelle Lernverfahren aus den Daten ableiten.
Sprachkonserven
Am primitivsten funktioniert Sprachsynthese, wenn ganze Wörter oder Teilsätze als akustische
Sprachkonserven nacheinander ausgegeben werden.
Dies funktioniert für eingeschränkte Anwendungsgebiete: "Jetzt. Bitte. Rechts. Abbiegen."
Beispiel 9.1.12 (Ein Problem zu einfacher Ansätze).
Speech Synthesis Markup Language (SSML)
Dieser XML-Standard erlaubt eine strukturierte Spezifikation von verschiedenen Parametern einer
Speech-Applikation.
http://www.w3.org/TR/2004/REC-speech-synthesis-20040907/
[ Weiter ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]