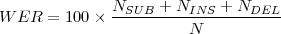Beispiel 9.2.4 (Assimilation).
- this year → this
 ear
ear
- the old man
 thiold man
thiold man
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Definition 9.2.1 (Speech Recognition System). Ein Spracherkennungssystem erzeugt aus dem akustischen Signal von gesprochener Sprache eine textuelle Darstellung.
Definition 9.2.2 (Speech Understanding System). Ein Sprachverarbeitungssystem berechnet aus dem akustischen Signal von gesprochener Sprache eine (partielle) Bedeutung.
Typische Architektur
Vom Sprachsignal zur Wortfolge
Wortübergänge (Junkturen)
Wortgrenzen werden eher selten als Sprechpausen realisiert.
Im Deutschen tendenziell durch die Erstbetonung. Im Englischen manchmal durch leichte Verlängerung beginnender Konsonanten oder Betonung endender Vokale.
Definition 9.2.3. Die Koartikulation ist die Beeinflussung der lautlichen Form eines Phonems durch seine Umgebung.
Beispiel 9.2.6 (Fehlsegmentierungen (Oronym)).
 nitrate ; grey day
nitrate ; grey day  grade A; why choose
grade A; why choose  white shoes
white shoes
 Thus add poetry members along a goat I’m
Thus add poetry members along a goat I’m
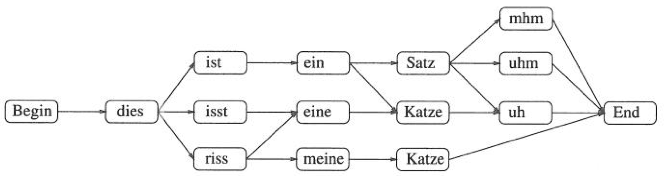
Worthypothesengraph
In einem Wortkandidatengraphen
werden kompakt alle möglichen Folgen von Wörtern repräsentiert.
Das Spracherkennungssystem sollte den in der Kommunikationssituation am wahrscheinlichsten Pfad auswählen.
Wortfehlerrate (word error rate, WER)
Definition 9.2.7 (Editierdistanz). Unter der minimalen Editierdistanz zweier Wortfolgen versteht man die minimale Anzahl der notwendigen Editieroperationen, um die Folgen gleich zu machen. Bei der Levenshtein-Editierdistanz können Wörter gelöscht (DEL), ersetzt (SUB) oder eingefügt (INS) werden.
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
 Chinaris
Chinaris
 besbuy
besbuy