Morphologieanalyse und Lexikonaufbau (8. Vorlesung)
Dozent: Gerold SchneiderKorpuslinguistik (im folgenden KL)
KL wird von vielen Computerlinguisten nur als Randgebiet der CL aufgefasst, aber:
Wörterbücher, Schul- und Fremdsprachengrammatiken werden häufig zu Rate gezogen, um den richtigen Gebrauch der Sprache sicherzustellen. Die Linguistik vergangener Jahrhunderte sah einen ihrer Hauptzwecke darin, den richtigen Gebrauch der Sparche zu kontrollieren: Präskriptive Linguistik.
Die deskriptive Linguistik hingegen beschreibt Sprache so, wie sie wirklich auftritt, inkl. Slang, ungrammatischen Äusserungen, Häufigkeit des Auftretens, Druckfehlern etc.
Dieses Unterkapitel basiert auf [McEnery 96] Chapter 1.
Unter Sprachkompetenz versteht man die Fähigkeit eines Spechers, wohlgeformte Sätze aufgrund von Sprachregeln zu bilden. Chomsky spricht auch von I(nternalisierter) Sprache und versteht darunter ein Regelsystem (z. B. Phrasenstrukturregeln und Transformationen), dass alle grammatischen Sätze generieren kann und alle ungrammatischen Sätze zurückweist.
Unter Performanz versteht man die Summe der Sprachäusserungen, die ein Sprecher einer Sprache von sich gibt. Chomsky spricht auch von E(xternalisierter) Sprache, eine extrem lange Auflistung aller Sätze, die in irgendeinem Kontext je geäussert wurden.
Kompetenz in diesem Sinne wird auch als Langue, Performanz in diesem Sinne auch als Parole bezeichnet.
Chomsky sah die Aufgabe der Linguistik vor allem darin, ein psycholinguistisches Modell der Sprachkompetenz zu bauen und verurteilte Performanz als einen untauglichen Spiegel der Kompetenz. Da Sprache unendlich ist, können nie je alle möglichen Sätze aufgelistet werden. Sprachregeln hingegen, so hoffte Chomsky, können z.b. aufgrund von Rekursion die Unendlichkeit aller möglichen Sätze beschreiben und liefern erst noch das psychologische Sprachmodell, nach dem Menschen funktionieren. Deshalb lehnte Chomsky die KL prinzipiell ab.
Chomsky schaffte es, zwischen Mitte der 50er und den 80er Jahren die Forschung in der KL fast ganz zum Erliegen zu bringen, bis man zu erkennen begann, dass das Chomskyanische Universalgrammatikmodell immer noch in endloser Ferne liegt und man Sprachdaten sinnvoll einsetzen kann
Letztlich geht es darum, dass Sprachwissenschaft an der Schnittstelle zwischen einer empirischen und einer rationalen Wissenschaft liegt. KL ist das systematische, streng empirische Vorgehen mit Beobachtung und Regelableitung, wie wir es aus anderen strengen Wissenschaften wie Physik und Mathematik kennen. Der Grammatiker, der introspektiv ein Sprachmodell nach seiner Intuition formt, geht dagegen in der Art des Rationalismus vor, wie in den Humanwissenschaften wie Philosophie und Geschichte üblich. Chomskys Erfindungen der X-bar Theorie, der Transformationen und leerer Knoten in der Syntax, die man alle nicht empirisch nachweisen kann, würden beispielsweise streng wissenschaftlichen Kriterien nicht genügen.
Diese intropektiv rationalen Linguisten, meditativ "im Lehnstuhl" denkend, nennt man auch Armchair Linguists, von Fillmore wie folgt karikiert:
"He sits in a deep soft armchair, with his eyes closed and his hands clasped behind his head. Once in a while he opens his eyes, sits up abruptly shoutin, 'Wow, what a neat fact!', grabs his pencil, and writes something down ... having come still no closer to knowing what language is really like."
Korpuslinguisten werden ebenso satirisch bedacht:
"He has all of the primary facts that he needs, in the form of a corpus of approximately one zillion running words, and he sees his job as that of deriving secondary facts from his primary facts. At the moment he is busy determining the relative frequencies of the eleven parts of speech as the first word of a sentence versus the second word of a sentence."
KL, da eher linguistisches Instrument als Teilgebiet der Linguistik, findet Anwendungen in fast allen linguistischen Teilgebieten, die zwei ersten sind für diese Vorlesung direkt relevant und werden vertieft behandelt. Die jeweiligen Punkte der folgenden Teilgebiete sind Beispiele und erheben keinen Vollständigkeitsanspruch:
[Biber 98] Chapter 2 ist ganz diesem Thema gewidmet.
Lexikographen sind schon seit Jahrhunderten bemüht, auf KL abzustützen. Samuel Johnson suchte schon 1755 mühevoll nach Beispielen aus der Literatur für die Einträge in seinem Lexikon. Heute gibt es kaum mehr ein Lexikon, das nicht KL-getestet ist: Kann jeder der Lexikoneinträge irgendwo in eine Text gefunden (belegt) werden? Wurde jedes (vielfach) vorkommende Wort ins Lexikon aufgenommen? Welche in Texten vorkommende Nominalkomposita soll man ins Lexikon aufnehmen (Kompositionalität)?
KL wird heute verwendet für:
KL-basierte Methoden erlauben zusätzlich lexikologische Angaben zu:
Gegeben sei folgende Trivialgrammatik und ein Parsingaufruf:
S -> NP VP. S -> NP. NP -> N N. NP -> N. VP -> 'walks'. NP -> 'walks'. N -> 'John'. Parse>> John walks.
Wie könnte man mit Hilfe eines annotierten Korpus der richtigen Lesart dieses Satzes Vorzug geben?
Häufig werden statistische Gewichtungen zur Disambiguierung von PP-Anbindung oder Adverbskopus verwendet:
John sees the man in the park with the telescope.
Welche Verben und welche Nomen verwenden welche Präpositionen mit Vorliebe?
Heureusement, Jean part pour les vacances. Jean heureusement survit l'accident.
Welche Verben und Adverben (oder Kombinationen) haben eher welchen Skopus?
In der Semantik gibt es z.B. Untersuchungen darüber, ob zwei synonymische Ausdrücke tendentiell von den gleichen Worten begleitet werden (Kollokationen). Es gibt auch Versuche, semantische Netzwerke zu konstruieren, bei denen (für referenzierende Worte) die durchschnittliche lokale Nähe im Text als Parameter der semantischen Nähe angenommen wird.
Ein grosser Teil der phonetischen KL untersucht Sprachvariation nach Alter, Dialekt, Ausbildung, Geschlecht etc. Korpora mit gesprochenen Daten sind aber auch interessant da sie noch näher an 'real-world' Sprachgebrauch sind als Textcorpora, also z.B. Grammatik so, wie sie 'in unseren Köpfen' lebt anstatt in Schulbüchern. Dies ist für die Psycholinguistik von Interesse. Viel linguistischen Wissen über Prosodie wurde auch durch Korpusanalysen gewonnen. Grosse Corpora gesprochener Sprache werden in der CL verwendet, um Spracherkennungssysteme möglichst sprecherunabhängig trainieren zu können.
Meist auch anhand gesprochener Korpora. Wer spricht wann, wie sind die Übergange zwischen Sprechern, wer unterbricht eine Äusserung, wie signalisieren Hörer ihr Interesse an gesprochenen?
Soziolinguistik ist per definition deskriptive Linguistik. Korpusbasierte Ansätze untersuchen Sprachvariation nach Alter, Dialekt, Ausbildung, Geschlecht und so weiter.
Den meisten qualitativen Veränderungen in der Sprache geht ein langer schleichender soziolinguistischer Prozess voran, in dem eine seltenere Form die üblichere immer stärker vertritt und diese mit der Zeit überflügelt. Nur quantitative Untersuchungen belegen die Präferenzen bei der Auswahl, die letztlich zu einere qualitativen Änderung führen.
Verschiedene Autoren bedienen sich verschiedener Stilmittel, was sich auch in der quantitativen Sprachbeschreibung niederschlägt. Welcher Autor braucht welche Worte häufiger, macht typischerweise welche Fehler, hat ungefähr welchen Substantiv/Verb Koeffizient etc. Die Stilometrie kann häufig Autoren unbekannter Werke identifizieren oder stellt sich die Frage, ob Shakespeare nur eine Person oder das Pseudonym einer Autorengruppe war.
Die Auswahl der Texte, die in einen Korpus aufgenommen werden sollen, ist entscheidend. Will man einen genrespezifischen oder einen allgemeinen Korpus zusammenstellen? Welche Texte repräsentieren welches Genre? Schwierig: Wie sollen verschiedene Genres in einem allgemeinen Korpus vertreten sein? Letztlich gibt es prinzipiell nie einen völlig ausgewogenen Korpus.
Alleine die Erkenntnis, dass ein gewisses Phänomen in einem Korpus häufiger als in einem anderen vorkommt, macht noch keine statistisch aussagekräftige Aussage. Eine dialektologische Untersuchung, die nur auf einen Probanden jeder Dialektgruppe abstützt, ist statistisch vollkommen wertlos, da die Unterschiede genausogut individueller Präferenzen anstatt dialektaler entspringen können.
Falls der zu untersuchende Häufigkeitsunterschied zwischen zwei (Teil-)Korpora gering ist oder falls nur eine kleine Anzahl Belege gefunden werden konnten, so ist das Risiko gross, dass es sich beim Unterschied nur um zufällige Fluktuationen handelt. Um den Einfluss zufälliger Schwankungen einschätzen zu können und somit echte von zufälligen Unterschieden trennen zu können, verwendet man eine Reihe von statistischen Tests. Siehe nächste Vorlesung.
Ein roher Text erlaubt nur klare Aussagen auf der Wortformenebene. Für gültige Aussagen auf der phonologischen, morphologischen, syntaktischen oder semantischen Ebene darf man sich nicht exklusiv auf fehlerbehaftete automatische Analysemethoden abstützen. Auf der morphologischen Ebene beispielsweise macht auch eine Taggingfehlerrate von nur 2% u.U. eine statistische Aussage völlig zunichte, falls sie teilweise auf die fehlerhaften Tags in einem so getaggten Korpus abstützt.
Deshalb ist es meist notwendig, sich auf zuverlässige, handkorrigierte oder -erstellte Analysen abzustützen, mit denen der Korpus annotiert ist. Eine Annotation auf möglichst vielen Ebenen ist zwar wünschenswert, verteuert und verlängert aber die Zusammenstellung eines Korpus ins Endlose. So beschränkt man sich meist auf wenige Ebenen oder der Korpus bleibt sehr klein. Für viele syntaktisch interessante Aussagen sind die meisten (aufwendig!) syntaktisch annotierten Korpora auch heute noch zu klein.
Als Beispiel einer morphosyntaktischen Annotation siehe STTS aus der ersten Vorlesung.
Die Verwaltung von grossen Datenmengen stellt Probleme in der Art der Speicherung, die schon auf einen einfachen und schnellen Zugriff vorbereiten soll.
Ein SQL-Abfragebefehl hat das folgende Format:
SELECT Zu findende Werte FROM Tabelle WHERE Bedingung
Stellen wir uns z.B. folgenden einfachen Korpusaufbau vor:
...
|
SATZ 2112 |
1 |
2 |
3 |
|
wort |
Ein |
Satz |
! |
|
tag |
DET |
NN |
PKT |
|
SATZ 2113 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
wort |
Der |
vorliegende |
Text |
ist |
ein |
Beispiel |
. |
|
tag |
DET |
ADJA |
NN |
VVFIN |
DET |
NN |
PKT |
|
SATZ 2114 |
1 |
2 |
3 |
4 |
5 |
|
wort |
Hier |
geht |
es |
weiter |
. |
|
tag |
ADV |
VVFIN |
PRO |
PTKVZ |
PKT |
Dann würde beispielsweise eine Anfrage nach den Artikeln im 2113. Satz des Korpus folgendes Aussehen haben, und liefert die darunterstehenden Ergbnisse:
SELECT wort FROM SATZ 2113 WHERE tag = DET > wort = Der > wort = ein > ALL RESULTS
#!local/bin/perl
# Dieses Prgramm sucht STTS Artikel, gibt sie aus und z"ahlt die Types
# (c) GS
while (<>) { # lese Korpus wortweise ein
($word, $tag) = split(/\_/); # trenne Wort und Tag bei _
if ($tag == "DET") { # ist es ein Artikel (DET)? Falls ja:
print "$word \n"; # gebe Wort aus
++$typecounter{$word}; # erhöhe den Zähler für dieses Wort um 1
}
} # Ende der while-Schleife: Nehme nächstes Wort
# und durchlaufe mit ihm die Schleife, etc.
Die extrahierten Daten, in der Regel lange Listen und Tabellen, geben oft noch keinen Überblick über die untersuchten Zusammenhänge. Hier empfiehlt sich der Einsatz eines professionellen Statistikprogrammes oder (für einfachere Aufgaben) des altbekannten MS Excel. Dazu ein Beispiel unten.
Dieses Kapitel ist ein historischer wie thematischer Abriss über den Aufbau der ersten grösseren computerlesbaren Korpora.
Schon 1964 begann in den USA ander Brown Universität (daher der Name Brown Corpus) die Zusammenstellung des ersten grösseren computerlesbaren Corpus. Die Zeiten waren schwierig; "it was compiled in the face of massive indifference if not outright hostility from those who espoused the conventional wisdom of the new and increasingly dominant paradigm in US linguistics led by Noam Chomsky" ([Kennedy 98] p. 23). Die damals immense angepeilte Korpusgrösse von 1 Mio Worte wurde innerhalb von 3 Jahren Arbeit erreicht. Im Bestreben um Ausgewogenheit wurden folgende Genres aufgenommen:
Aufteilung des Brown und des LOB Korpus
Category A (Press: reportage) Category B (Press: editorial) Category C (Press: reviews) Category D (Religion) Category E (Skills, trades and hobbies) Category F (Popular lore) Category G (Belles lettres, biography, essays) Category H (Miscellaneous, mainly Government documents) Category J (Learned and scientific writings) Category K (General Fiction) Category L (Mystery and detective fiction) Category M (Science fiction) Category N (Adventure and western fiction) Category P (Romance and love story) Category R (Humour)
Diesseits des Atlantik standen erst in den 70er Jahren genügend Ressourrcen zur Verfügung um ein ähnliches Projekt in Angriff zu nehmen. Von 1970-78 wurde als gemeinsames Projekt der beteiligten Universitäten der Lancaster-Oslo-Bergen (LOB) Korpus zusammengestellt, nach der gleichen Aufteilung wie der Brown Korpus, ebenfalls mit etwa 1 Mio Worten, womit beispielsweise erstmals ein qunatitativer Vergleich zwischen US und GB Englisch möglich wurde.
1988 folgte ein fast gleich aufgeteilter Korpus für Indisches Englisch, darauf ebenso einer für Australisches, und 1993 einer für Neuseeländisches Englisch. Auch heute noch finden diese Korpora weite Verwendung, nicht zuletzt weil sie klein genug sind um auf heute üblichen PCs bearbeitet zu werden.
Schon in den 70er Jahren wurden erste Versuche zum semi-automatischen part-of-speech Tagging vorgenommen. Die Fehlerraten waren aber noch sehr hoch. Erst das für den LOB Korpus entwickelte CLAWS System erreichte Fehlerraten von unter 5%. Die manuelle Korrektur bleibt aufwendig, im Falle das LOB Korpus erfolgte sie zwischen 1978 und 1983.
Teile diser Korpora liegen auch schon syntaktisch annotiert in hierarchischer Phrasenstruktur vor, aber noch keiner von ihnen vollständig. Parsing und manuelle Korrektur sind noch wesentlich aufwendiger als fürs part-of-speech Tagging.
Heute gibt es viele Spezialkorpora in Englisch, für gesprochenes Englisch, diachrone Sprachentwicklung, Spracherwerb etc. Auch fürs deutsche sind schon einige erhältlich (z.B. der STTS-annotierte Frankfurter Rundschau Korpus mit etwa 250'000 Worten oder der kleine von uns STTS-annotierte Zürcher Universitätskorpus mit 50'000 Worten).
Im Englischen wird die Entwicklung von extrem grossen Corpora vorangetrieben. Der aus dem Cobuild-Projekt entstandene, allerdings ungeaggte Bank of English Korpus umfasst etwa 300 Mio Worte. Der British National Corpus (BNC) ist ähnlich wie Brown oder LOB getaggt und umfasst 100 Mio Worte, aber es ist fraglich, wieviele Taggingfehler die gezwungenermasse oberflächliche Korrektur des automatischen Tagging noch überlebt haben. Am Englischen Seminar der Uni Zürich ist Prof. Totties Gruppe an der BNC-Forschung vertreten.
[Kennedy 98] Chapter 2.3 bietet einen Überblick über einige weitere Korpora.
Ein Konkordanzprogramm erlaubt
Conc (derzeitge Version ist 1.80b3) kann man hier frei herunterladen vom amerikanischen Summer Institute of Linguistics (www.sil.org). Es ist relativ einfach, sowohl in der Bedienung als auch in den Möglichkeiten. Es verwendet z.B. Korpora in rohem Textformat, was maximal einfach ist, aber lange Verarbeitungszeiten zum Aufbau der Konkordanz mit sich zieht. Ein Nachteil der Einfachheit ist auch, dass der ganze Korpus im RAM Platz finden muss.
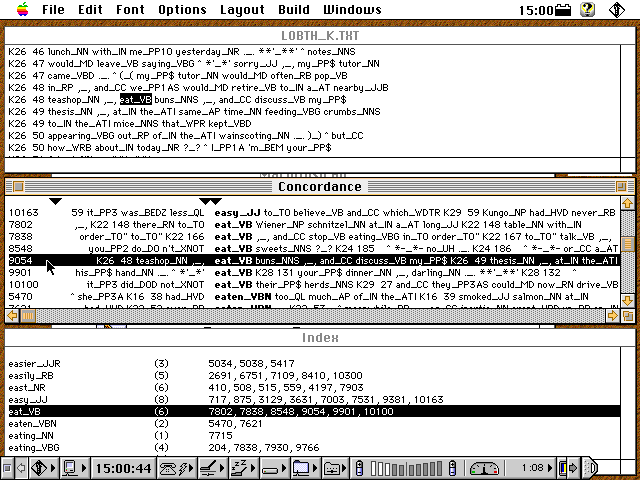
Eine Ausschnitt einer Konkordanz der Kategorie K (General Fiction) des wort-getaggten Lancaster-Oslo Bergen (LOB) Korpus sieht wie folgt aus:
[Schnappschuss 1: Conc-Konkordanz mit LOB Korpus Kategorie K, Sortierfolge ASCII]
Die einzelnen Ansichten sind miteinander verlinkt und ergeben einen ersten Überblick.
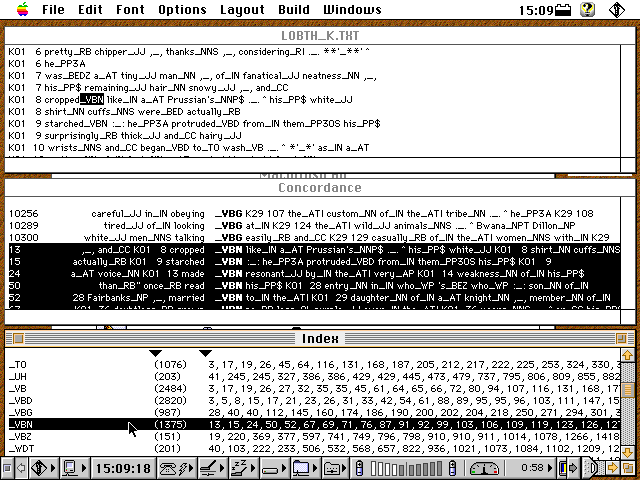
Statt direkt auf der Wortebene kann man auch auf der Tag-Ebene suchen. Das Tag _VBN (Verb Past Particple) trat beispielsweise 1375 mal auf in LOB K
[Schnappschuss 2: Conc-Konkordanz mit LOB Korpus Kategorie K, sortiert nach Tags]
Einfache quantitative Untersuchungen kann man schon in Conc selber vornehmen. So z.B.:
Wir beschränken uns auf einen Direktvergleich der LOB Kategorien K (General Fiction) und J (Learned and Scientific Writing) und versuchen, die folgenden einfachen Fragen zu beantworten:
Um die Tags für Verben und Nomen zu identifizieren bedienen wir uns einer Auflistung des Tagsets, wie hier folgt:
THE TAGGED LOB CORPUS: LIST OF TAGS Each word and punctuation mark is followed by a tag, as listed below. Example: the_ATI house_NN. Some tags occur with ditto marks. Example: as_IN to_IN" (complex preposition). Ditto tagging is used to deal with special types of sequences. For more information, see the manual for the tagged LOB Corpus. ! exclamation mark &FO formula &FW foreign word ( left bracket ) right bracket *' open single quotes **' close single quotes *- dash , comma ----- new sentence marker . full stop ... ellipsis : colon ; semicolon ? question mark ABL pre-qualifier (QUITE, RATHER, SUCH) ABN pre-quantifier (ALL, HALF) ABX pre-quantifier/double conjunction (BOTH) AP post-determiner (FEW, FEWER, FEWEST, LAST, LATTER, LEAST, LESS, LITTLE, MANY, MORE, MOST, MUCH, NEXT, ONLY, OTHER, OWN, SAME, SEVERAL, VERY) AP$ OTHER'S APS OTHERS APS$ OTHERS' AT singular article (A, AN, EVERY) ATI singular or plural article (THE, NO) BE BE BED WERE BEDZ WAS BEG BEING BEM AM, 'M BEN BEEN BER ARE, 'RE BEZ IS, 'S CC coordinating conjunction (AND, AND/OR, BUT, NOR, ONLY, OR, YET) CD cardinal (2, 3, etc.; TWO, THREE, etc.; HUNDRED, THOUSAND, etc.; DOZEN, ZERO) CD$ cardinal + genitive CD-CD hyphenated pair of cardinals CD1 ONE, 1 CD1$ ONE'S CD1S ONES CDS cardinal + plural (TENS, MILLIOBS, DOZENS, etc.) CS subordinating conjunction (AFTER, ALTHOUGH, etc.) DO DO DOD DID DOZ DOES DT singular determiner (ANOTHER, EACH, THAT, THIS) DT$ singular determiner + genitive (ANOTHER'S) DTI singular or plural determiner (ANY, ENOUGH, SOME) DTS plural determiner (THESE, THOSE) DTX determiner/double conjunction (EITHER, NEITHER) EX existential THERE HV HAVE, 'VE HVD HAD past tense, 'D HVG HAVING HVN HAD past participle HVZ HAS, 'S IN preposition (ABOUT, ABOVE, etc.) JJ adjective JJB attributive-only adjective (CHIEF, ENTIRE, MAIN, etc.) JJR comparative adjective JJT superlative adjective JNP adjective with word-initial capital (ENGLISH, GERMAN, etc.) MD modal auxiliary NC cited word NN singular common noun NN$ singular common noun + genitive NNP singular common noun with word-initial capital (ENGLISHMAN, GERMAN, etc.) NNP$ singular common noun with word-initial capital + genitive NNPS plural common noun with w.i.c. NNPS$ plural common noun with w.i.c. + genitive NNS plural common noun NNS$ plural common noun + genitive NNU abbreviated unit of measurement unmarked for number (\0HR, \0LB, etc.) NNUS abbreviated plural unit of measurement (\0GNS, \0YDS, etc.) NP singular proper noun NP$ proper noun + genitive NPL locative noun with w.i.c. (ABBEY, BRIDGE, etc.) NPL$ locative noun with w.i.c. + genitive NPLS plural locative noun with w.i.c. NPLS$ plural locative noun with w.i.c. + genitive NPS plural proper noun NPS$ plural proper noun + genitive NPT titular noun with w.i.c. (ARCHBISHOP, CAPTAIN, etc.) NPT$ titular noun with w.i.c. + genitive NPTS plural titular noun with w.i.c. NPTS$ plural titular noun with w.i.c. + genitive NR adverbial noun (JANUARY, FEBRUARY, ETC.; SUNDAY, MONDAY, etc.; EAST, WEST, etc.; TODAY, TOMORROW, TONIGHT; DOWNTOWN, HOME) NR$ adverbial noun + genitive NRS plural adverbial noun NRS$ plural adverbial noun + genitive OD ordinal (1st, 2nd, etc.; FIRST, SECOND, etc.) OD$ ordinal + genitive PN nominal pronoun (ANYBODY, ANYONE, ANYTHING; EVERYBODY, EVERYONE, EVERYTHING; NOBODY, NONE, NOTHING; SOMEBODY, SOMEONE, SOMETHING; SO) PN$ nominal pronoun + genitive PP$ possessive determiner (MY, YOUR, etc.) PP$$ possessive pronoun (MINE, YOURS, etc.) PP1A I PP1AS WE PP1O ME PP1OS US, 'S PP2 YOU PP3 IT PP3A HE, SHE PP3AS THEY PP3O HIM, HER PP3OS THEM, 'EM PPL singular reflexive pronoun PPLS plural reflexive pronoun, reciprocal pronoun QL qualifier (AS, AWFULLY, LESS, MORE, SO, TOO, VERY, etc.) QLP post-qualifier (ENOUGH, INDEED) RB adverb RB$ adverb + genitive (ELSE'S) RBR comparative adverb RBT superlative adverb RI adverb (homograph of preposition: BELOW, NEAR, etc.) RN nominal adverb (HERE, NOW, THERE, THEN, etc.) RP adverbial particle (BACK, DOWN, OFF, etc.) TO infinitival TO UH interjection VB verb, base form VBD verb, past tense VBG present participle, gerund VBN past participle VBZ verb, 3rd person singular WDT WH-determiner (WHAT, WHATEVER, WHATSOEVER, interrogative WHICH, WHICHEVER, WHICHSOEVER) WDTR WH-determiner, relative (WHICH) WP WH-pronoun, interrogative, nom+acc (WHO, WHOEVER) WP$ WH-pronoun, interrogative, gen (WHOSE) WP$R WH-pronoun, relative, gen (WHOSE) WPA WH-pronoun, nom (WHOSOEVER) WPO WH-pronoun, interrogative, acc (WHOM, WHOMSOEVER) WPOR WH-pronoun, relative, acc (WHOM) WPR WH-pronoun, relative, nom+acc (THAT, relative WHO) WRB WH-adverb (HOW, WHEN, etc.) XNOT NOT, N'T ZZ letter of the alphabet (E, PI, X, etc.)
Grob gesagt beginnen Verbtags mit V und Nomentags mit N. Die einfache in Conc eingebaute Statistikabfrage über reguläre Ausdrücke liefert uns dazu folgende Ergebnisse:
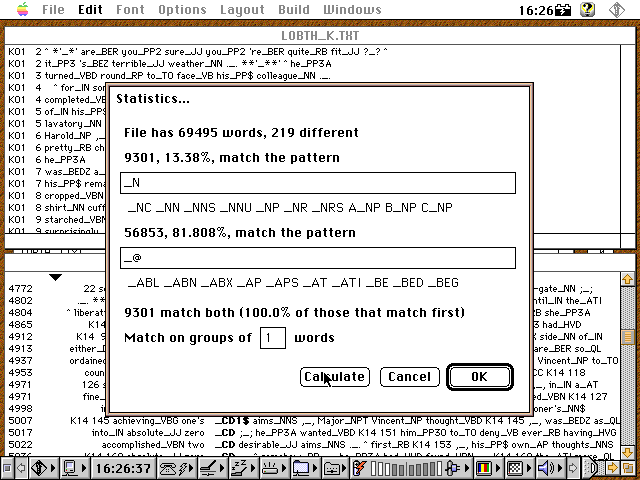
[Schnappschuss 3: Substantivprozentanteile in LOB K (General Fiction)]
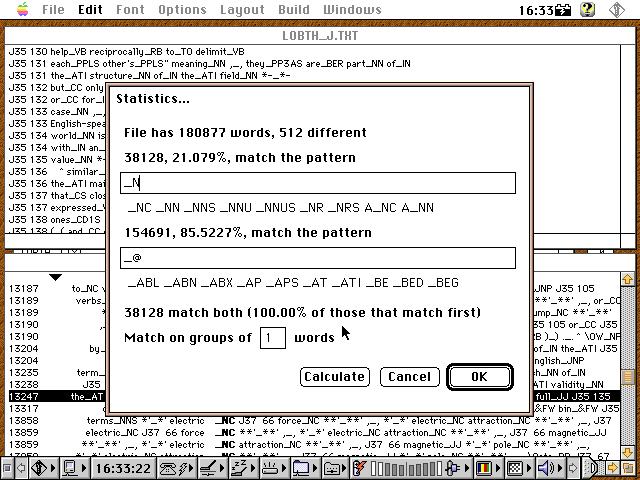
[Schnappschuss 4: Substantivprozentanteile in LOB J (Learned and Scientific Writing)]
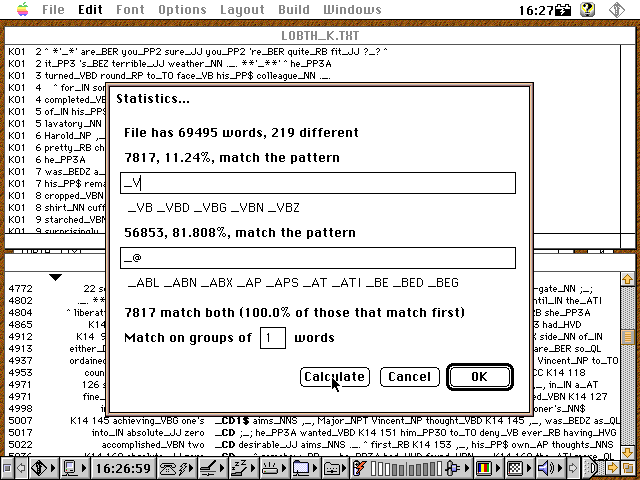
[Schnappschuss 5: Verbprozentanteile in LOB K (General Fiction)]
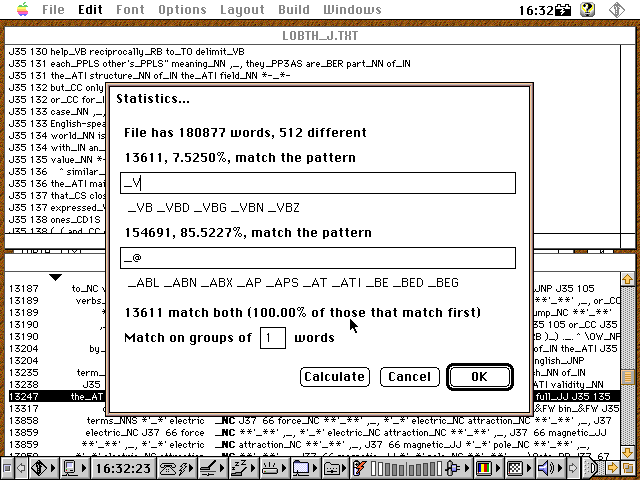
[Schnappschuss 6: Verbprozentanteile in LOB J (Learned and Scientific Writing)]
Vielleicht ist man aber nicht nur an einer Grobanalyse interessiert, sondern will die einzelnen Verb- und Nomen-Unterklassen miteinander vergleichen. Für eine detailliertere Analyse der Ergebnisse kann man Konkordanzen erstellen, die gezielt alle _N und _V Tags untersucht.
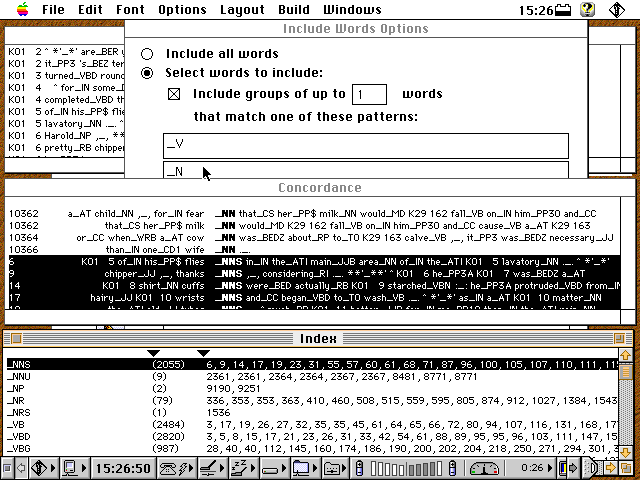
[Schnappschuss 7: LOB K, tagsortiert nur über _N und _V]
FRAGE: Erreichen wir mit dieser Anordnung unser Ziel, alle Nomen und Verben der beiden Teilkorpora miteinander zu vergleichen?
Nach der Wahl einer umfassenderen Abfrage sehen die Ergebnislisten oft ziemlich komplex aus und der Überblick kann nicht mehr direkt gewonnen werden. Eine graphische Visualisierung macht die Zahlen greifbar.
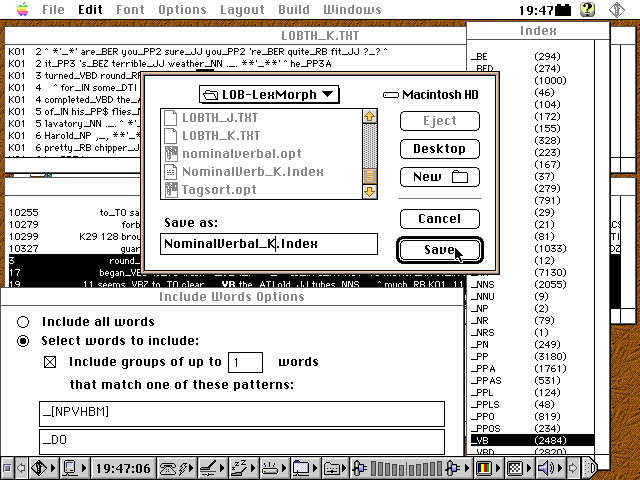
[Schnappschuss 8: Export des komplexeren Index von LOB K]
Der Index liegt nun als Textfile vor, welches direkt in Excel importiert werden kann. Nach ein paar Copy-Paste Operationen kann die Nachbearbeitung einsetzen:
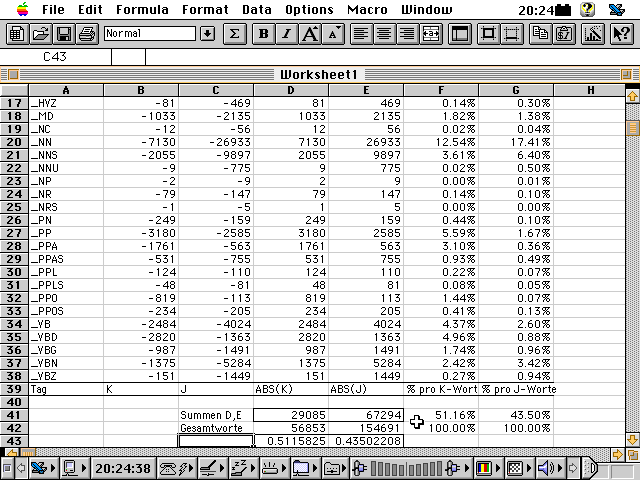
[Schnappschuss 9: Import des komplexeren Index von LOB K und LOB J (Zeilen bis 38, Spalten A bis C) und einsetzende Weiterbearbeitung]
Die so gewonne Tabelle lässt sich in diversen Tabellenformen darstellen. Es gibt aber noch zuviele Parameter, als dass man mehr als ein paar vage Trends ablesen könnte.
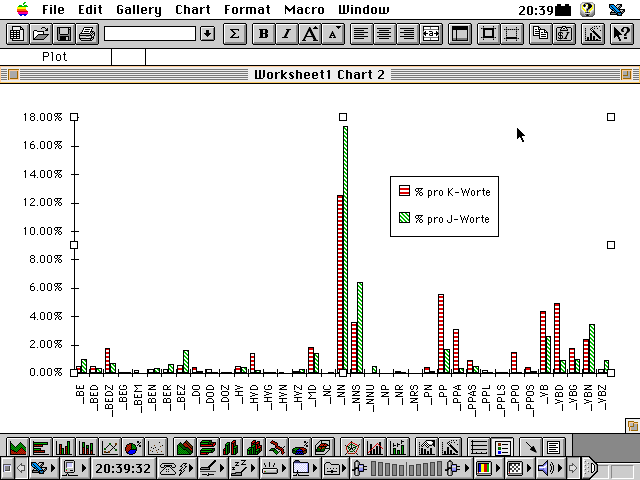
[Schnappschuss 10: Noch kein Musterknabe an Übersichtlichkeit]
Ein möglicher nächster Schritt besteht darin, die Untergruppen zusammenzufassen.
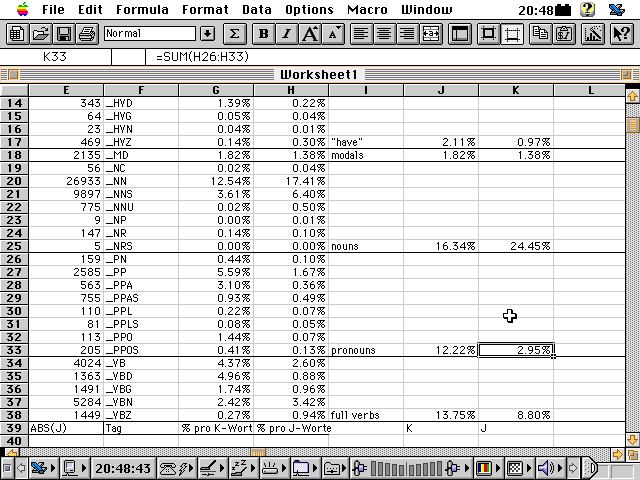
[Schnappschuss 11: Zusammenfassen der Untergruppen]
Nun liefert die graphische Visualisierung einen Überblick.
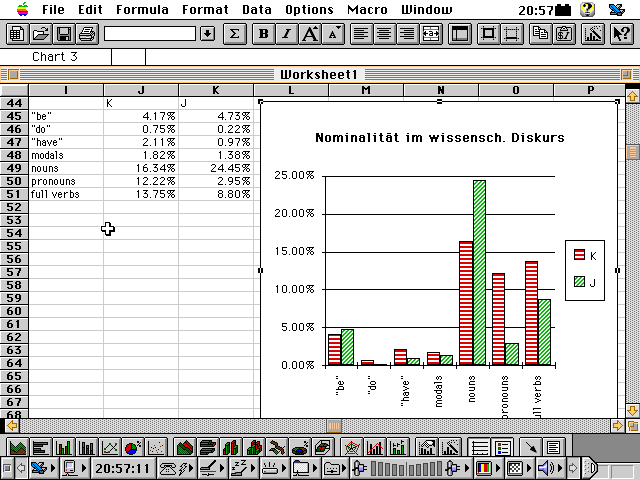
[ Schnappschuss 12: Überblick über die Nominalitätshypothese]