Intelligent Assistance for the Data Mining Process: An Ontology-based Approach
Knowledge discovery from data is the result of an exploratory process involving the application of various algorithmic procedures for manipulating data, building models from data, and manipulating the mod-els. The Knowledge Discovery (KD) process [Fayyad, Piatetsky-Shapiro & Smyth, 1996] is one of the central notions of the field of Knowledge Discovery and Data mining (KDD). The KD process deserves more attention from the research community; processes comprise multiple algorithmic components, which interact in non-trivial ways. Even data-mining specialists are not familiar with the full range of components, let alone the vast design space of possible processes. Therefore, both novices and data-mining specialists are apt to overlook useful instances of the KD process. We consider tools that will help data miners to navigate the space of KD processes (see Figure 1) systematically, and more effectively.

Figure 1: The KD process (adapted from Fayad et al. [1996])
Figure 2 shows three simple, example DM processes. Process 1 comprises simply the application of a decision-tree inducer. Process 2 preprocesses the data by discretizing numeric attributes, and then builds a naïve Bayesian classifier. Process 3 preprocesses the data first by taking a random subsample, then applies discretization, and then builds a naïve Bayesian classifier.
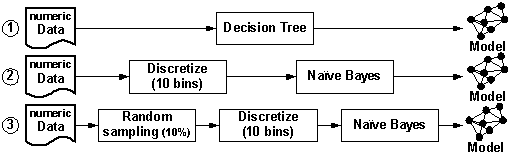
Figure 2: Three valid DM processes Intelligent
Discovery Assistants (IDAs) help data miners with the exploration of the space of valid DM processes. A valid DM process violates no fundamental constraints of its constituent techniques. For example, if the input data set contains numeric attributes, simply applying naïve Bayes is not a valid DM process-because (strictly speaking) naïve Bayes applies only to categorical attributes. However, Process 2 is valid, because it preprocesses the data with a discretization routine, transforming the numeric attributes to categorical ones. IDAs take advantage of an explicit ontology of data-mining techniques, which defines the various techniques and their properties. Using the ontology, an IDA searches the space of valid processes. Applying each search operator corresponds to the inclusion in the DM process of a different data-mining technique; preconditions constrain its applicability and there are effects of applying it. Figure 3 shows some (simplified) ontology entries (cf., Figure 2).

In this project we investigate the following benefits of IDA. In particular, we believe that IDAs can provide users with
- a systematic enumeration of valid DM processes, so they do not miss important, potentially fruitful options
- effective rankings of these valid processes by different criteria, to help them choose between the options
- an infrastructure for sharing knowledge about data-mining processes, which leads to what economists call network externalities.
Current Project Participants
- Prof. Abraham Bernstein, University of Zurich
- Prof. Foster Provost, New York University, Stern School of Business
- Shawndra Hill, New York University, Stern School of Business
Relevant Publications
- Bernstein, Abraham, Shawndra Hill, and Foster Provost. 2002.
An Intelligent Assistant for the Knowledge Discovery Process: An Ontology-based Approach
New York University – Leonard Stern School of Business, Center for Digital Economy Research, CeDER Working Paper # IS-02-02
PDF-file - Bernstein, Abraham, and Foster Provost. 2001
An Intelligent Assistant for the Knowledge Discovery Process
New York University - Leonard Stern School of Business, Center for Digital Economy Research, CeDER Working Paper # IS-01-01
also to be presented at the
IJCAI 2001 Workshop on Wrappers for Performance Enhancement in Knowledge Discovery in Databases
PDF-file