13.1
Motivation
Kontextfreie Grammatiken für natürliche Sprachen
Die rohe Verwendung kontextfreier Grammatiken erzeugt für Sprachen mit ausgebauter Morphologie
ein Unmenge Regeln.
Beispiel 13.1.1 (Übereinstimmung von Kasus, Genus und Numerus in NP).
Für morpho-syntaktisch korrekte Phrasen muss etwa statt
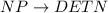
eine
Vielzahl spezifischerer Regeln verwendet werden.
Wieviele sind es für Deutsch?
Probleme kontextfreier Grammatikentwicklung
- Generalisierungen
wie «Artikel und Kernnomen haben innerhalb einer NP immer dasselbe Genus und denselben
Kasus und Numerus» lassen sich nicht explizit
formulieren.
- Die Regelvervielfältigung
verdunkelt Generalisierungen der Konstituenz. Das Symbol «NpFemSgNom» hat nur
mnemotechnisch etwas mit «NpMascSgNom» zu tun – strukturell gibt es keinen
Bezug.
- Ausweg: Trennung von grundlegenden Regeln von den morpho-syntaktischen Merkmalen
Probabilistische kontextfreie Grammatiken
Relevant ist dies mehr für linguistisch orientierte Grammatikentwicklung – syntaktische Analyse ist
möglich mit kontextfreien Grammatiken, welche oft Zehntausende von Regeln enthalten. Dies ist bei
probabilistischen Parsern durchaus üblich.
Probleme kontextfreier Grammatikentwicklung
Kontextfreie Grammatikregeln kodieren Konstituenz
und Präzedenz (Reihenfolge der Teilkonstituenten
) immer gleichzeitig. Sprachen mit freierer Wortstellung bzw. Satzgliedstellung wie etwa im Deutschen
müssen damit umständlich beschrieben werden.
ID/LP-Regeln
Einige Grammatikformalismen erlauben die separate Angabe von unmittelbarer Dominanz (ID,
immediate dominance) und Präzedenz (LP, linear precedence). LP-Regeln gelten typischerweise global
für eine Grammatik.
Beispiel 13.1.2 (ID/LP-Regeln in XLE).
Eine NP enthält einen Artikel D und ein Nomen N. Der Artikel muss dem Nomen vorangehen.
NP --> [D , N] & D < N.
Kontextfreies Gerüst in XLE
PSG ENGLISH RULES (1.0)
S --> NP VP .
NP --> { D N
| PN } .
VP --> V (NP).
PSG ENGLISH LEXICON (1.0)
bark V * .
barks V * .
like V * .
likes V * .
the D * .
two D * .
he PN * .
him PN * .
dog N * .
dogs N * .
Wie viele Sätze kann man mit dieser Grammatik ableiten?


