|
|
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Chunking mit Longest-Matching-Strategie
[BEESLEY und KARTTUNEN 2003b, 74] geben eine einfache Regel zur NP-Erkennung (d=Det; a= Adj; n=Noun; v=Verb):
Problem
Wie kann man aus dieser Idee einen richtigen Chunker machen?
Input für getaggten Text im Penn-Treebank-Format
Input-Klammerformat: ( POS-TAG SPACE WORD )
(JJ U.K.)(NN base)(NNS rates)(VBP are)(IN at)(PRP$ their)(JJS highest)(NN level)(IN in)(CD eight)(NNS years)(. .)
Output-Klammerformat mit zusätzlicher Klammerung
(NP (JJ U.K.)(NN base)(NNS rates))(VBP are)(IN at) (NP (PRP$ their)(JJS highest)(NN level) )(IN in) (NP (CD eight)(NNS years) )(. .)
Schützen von wörtlichen Klammern
Für eine korrekte Verarbeitung müssen alle Klammern, welche im Text als Interpunktion oder als Teil von POS-Tags vorkommen, geschützt werden. Konventionell wird in der Penn-Treebank “-RRB-” für “)” und “-LRB-” für “(” verwendet.
POS-Tags, Wörter und Input-Sprache ▸▸▸
Automatische Evaluation des Chunkers
Um die Qualität des Chunkers quantifizieren zu können, empfiehlt sich eine automatische Evaluation
gegenüber einem sog. Gold-Standard.
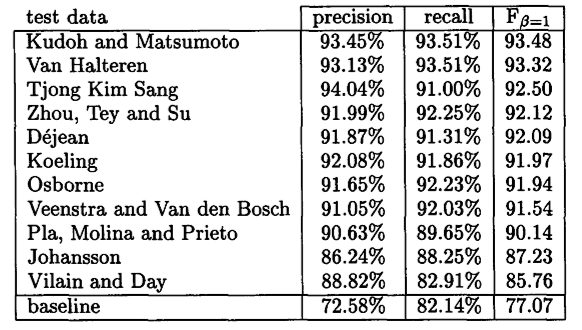
Resultate der Chunking-Shared-Task der CoNLL 2000
|
|
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]