15.4. Methoden der TE
15.4.1. Linguistische Methoden der TE
Identifiziere spezifisch fachsprachliche Wortbestandteile!
- Affixe
, d.h. Präfixe oder Suffixe matchen. Medizin: “-itis”, “-aemia”, “hypo-”, “peri-” wie in
“hyperimmunoglobulinaemia”
- Stämme
matchen. Elektrotechnik: “-impuls-” wie in “Hardwareimpuls” oder “24-Volt-Impusgeber”
Diskussion
- Direkt nur für einteilige Termini verwendbar.
- Eng auf Anwendungsbereich abgestimmt (schlecht für kommerzielle Allzweck-TE).
- Sprachübergreifend ähnliche Affixe und Stämme
helfe bei bilingualer TE: “Hypo-Hyperparathyreoidismus”, “hypo-hyperparathyroïdisme”,
“hypo-hyperparathyroidis”
Identifiziere Termkandidaten anhand der Wortarten!
Sprachspezifische Wortgruppenmuster für Nominalphrasen
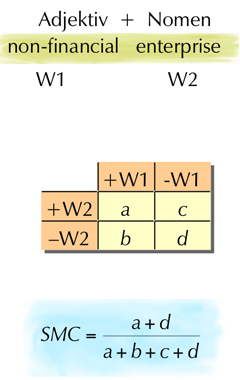
- Adjektiv + Nomen: “non-financial enterprise”
- Nomen + Nomen: “interbank market”
- Nomen + “of”-Präposition + Adjektiv + Nomen: “settlement of cross-border payments”
Probleme
- Viel Noise! Insbesondere, wenn das Muster “Nomen” für einteilige Termkandidaten
zugelassen ist!
- Ausweg
: Verwendung von Stoppwortlisten (manuell erstellt oder Sammlung hochfrequenter
allgemeinsprachlicher Vokabeln)
Exkurs Xerox TermFinder
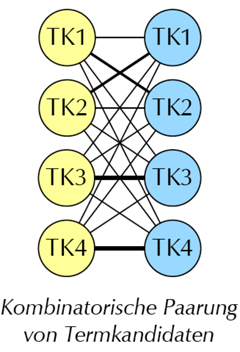
Bilinguale Termextraktion à la Xerox Termfinder
- Extrahiere monolingual in beiden satzalignierten Paralleltexten alle Nominalphrasen über
Wortgruppenmuster als Termkandidaten!
- Bilde bilinguale Termkandidaten, indem alle monolingualen Termkandidaten aus jedem
Parallelsatz miteinander gepaart werden!
Problem und Ausweg
- Unzählige falsche Kombinationen!
- Automatisches Ausfiltern schlechter Paare mit Heuristiken (Daumenregeln) zu
Übereinstimmung vonTermlänge, interner Struktur etc.
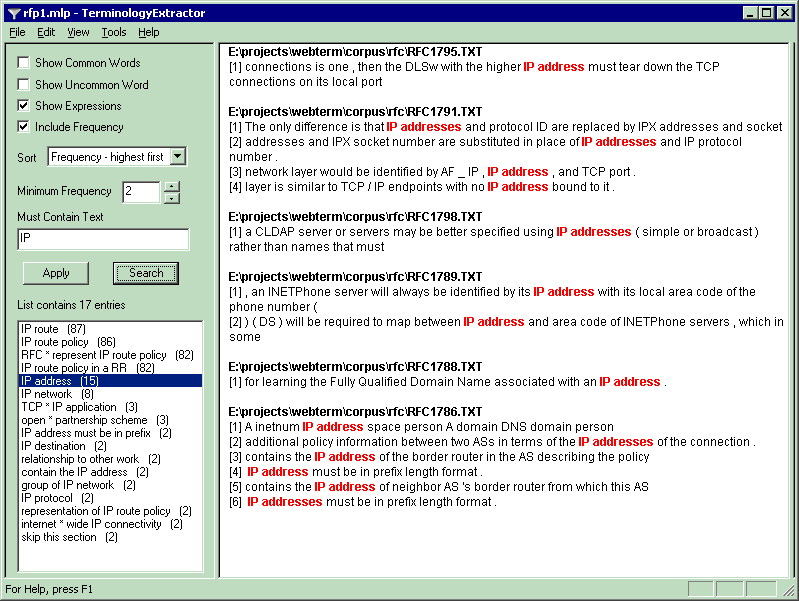
Exkurs Chamblon TerminologyExtractor
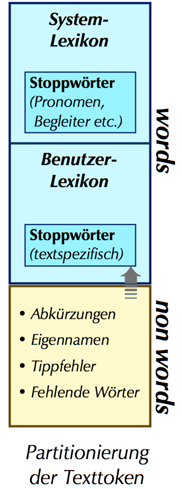
Monolinguale Termextraktion für Englisch/Französisch
- Partitioniere
die Tokens der Texte in unbekannte Wortformen (non words) und dem Lexikon bekannte
Grundformen (words)!
- Systemlexikon
(E/F) mit Lemmatisierung und eingebauter Stoppwortliste
- Benutzerlexikon
erlaubt Erweiterungen für beide Kategorien.
- Extrahiere
die häufigsten N-Gramme (Kollokationen) aus words und non words!
- Ignoriere reine Stoppwortkollokationen
und Stoppwörter an Kollokationsrändern!
- Ignoriere eingebettete Kollokationen
, ausser sie sind häufiger als die umfassendere Kollokation!
15.4.2. Quantitative Methoden der TE
Quantitative Methoden der TE I
Identifiziere Termkandidaten wegen deren abweichenden Vorkommenshäufigkeit!
Idee
Fachwörter kommen in Fachtexten (SL) häufiger vor als in allgemeinen Texten (GL).
Definition 15.4.1 (Relative Häufigkeit eines Worts im Text).
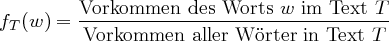
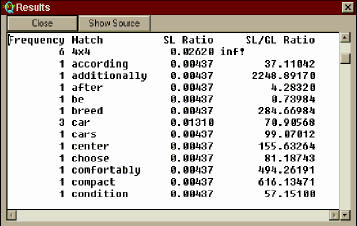
Definition 15.4.2 (Weirdness: Falls hoher Wert, dann Termkandidat!).
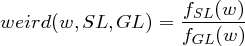
Bedingungen
- Für TE erst brauchbar bei Vorkommen > 4!
- Geeignet für einteilige Termini. Ausser: Wortgruppen werden als Einheit betrachtet und
gezählt!
- Relativ sprachunabhängig
Dokumentenbezogene Masse
Idee
Fachwörter treten nur in bestimmten Dokumenten auf – dort aber gehäuft!
Fachbegriffe als gute Dokumentdeskriptoren
Zwei wichtige Masse aus dem Information Retrieval zur Quantifizierung der inhaltlichen Relevanz von
Wörtern für ein bestimmtes Dokument lassen sich verwenden:
- Termhäufigkeit
(TF): Wie oft kommt Term t in Dokument d vor?
- Inverse Dokumenthäufigkeit
(IDF): Wieviele Dokumente enthalten Term t (nicht)?
Mehrteilige Termkandidaten identifizieren
Idee der hohen Assoziationsstärke
Bestandteile von Termini treten auffällig häufig miteinander auf!
Kontingenztabelle
- = W1 und W2 kommen beide vor
- = W1 kommt ohne W2 vor
- = W2 kommen ohne W1 vor
- = weder W1 noch W2 kommt vor
Gezählt wird über allen Wortgruppen.
Assoziationsmass
SMC (Simple Matching Coefficient) ist einfach und brauchbar. Viele weitere Masse!
Bilinguales Zuordnen von Kandidaten (term alignment)
Ansatz nach [VINTAR 2002]
- Kompilation von bidirektionalen, probabilistischem Lexika (word alignment) aus
Paralleltexten
- Alignierung eines (mehrteiligen) Terms T mit Z:
- Nimm alle Übersetzungen der Bestandteile von T
- Aligniere mit demjenigen Zielterm Z, dessen Bestandteile die höchste Summe der
Wahrscheinlichkeiten der Übersetzungen von T aufweisen.
Probleme
- Seltene Wörter haben schlechte probabilistische Lexikoneinträge
- Zuordnen von einteiligen (Komposita) zu mehrteiligen Termini
Beispiel für Zuordnung nach Vintar
15.4.3. Anwendung
Anwendungspotential
Bilinguale Termextraktion im Kontext von CAT-Systemen zur technischen Redaktion
- noch engere Verknüpfung mit den Methoden der computergestützten Übersetzung
(translation memories)
- Extraktion
von Termkandidaten vor der Übersetzung
- Intelligenter Look-up
während der Übersetzung
- Konsistenzprüfungen
nach der Übersetzung
Bilinguale Termextraktion für Informationssuche
CLIR (cross language information retrieval)
Monolinguale Terminologieextraktion
bleibt schwierig: Professionalisierung, Outsourcing
Methodische Entwicklungen
Verbesserte hybride Ansätze
- Das Beste der linguistischen und statistischen Methoden kombinieren
- Integration von robusten linguistischen Technologien (partielle syntaktische Analyse)
- Hauptziel: Verminderung von Noise
, d.h. höhere Präzision
- Erkennen von Termvarianten
Nutzen bestehender terminologischer Bestände
Intelligente Integration von elektronisch verfügbaren Ressourcen: Terminologien, translation memories,
Thesauri, Ontologien.