|
|
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Extraktion lexikalischer Relationen aus einem Wörterbuch
Projekt-Idee
[ALSHAWI 1987] extrahiert lexikalische Information aus einem maschinenlesbaren Wörterbuch (MRD = machine readable dictionary): dem “Longman Dictionary of Contemporary English” (LDOCE).
Motivationen
|
|
Aufgabe der Analyse
Mini-Evaluation
Beispiel: Regeln für Relativsätze
Pattern-Ansatz von [HEARST 1992]
Motivation und Hauptziele
Nachteile
Die Methode scheint besonders gut für Hyponymie zu funktionieren – andere Relationen sind schwierig.
Text aus Grolier’s American Academic Encyclopedia
The bow lute, such as the Bambara ndang, is plucked and has an individual curved neck.
Idee
Auch wenn man “Bambara ndang” noch nie gehört hat, weiss man, dass es eine Art “bow lute” sein muss.
Lexikalisch-syntaktisches Muster
Aus
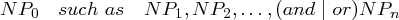
hyponym("Bambara ndang","bow lute")
Problem der Modifikation
In einem Zeitungstext (New York Times) mit ca. 20 Millionen Wörtern finden sich etwa 3178 Sätze mit dem “such-as”-Muster. Aber nur 46 Relationen lassen sich damit identifizieren, wenn man keine modifizierten Nomen erlaubt.
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]

