11.4. Anwenden
11.4.1. Lemmatisierung
Problem der Mehrdeutigkeit der Wortart
Mehrdeutigkeit der Wortart
Beispiel 11.4.1 (GERTWOL-Analysen für “Eine Frage überlebt”).
"<*eine>"
"ein" * ART INDEF SG NOM FEM
"ein" * ART INDEF SG AKK FEM
"einer" * PRON INDEF SG NOM FEM
"einer" * PRON INDEF SG AKK FEM
"ein~en" * V IND PRÄS SG1
"ein~en" * V KONJ PRÄS SG1
"ein~en" * V KONJ PRÄS SG3
"ein~en" * V IMP PRÄS SG2
"<überlebt>"
"über|leb~en" V IND PRÄS PL2
"über|leb~en" V IMP PRÄS PL2
"über|leb~en" V IND PRÄS SG3
"über|leb~en" V PART PERF
"über|leb~en" V TRENNBAR IND PRÄS PL2
"über|leb~en" V TRENNBAR IND PRÄS SG3
"über|lebt" A(PART) POS
"üb#er|lebt" A(PART) POS
"<*frage>"
"*frag~e" S FEM SG NOM
"*frag~e" S FEM SG AKK
"*frag~e" S FEM SG DAT
"*frag~e" S FEM SG GEN
"frag~en" * V IND PRÄS SG1
"frag~en" * V KONJ PRÄS SG1
"frag~en" * V KONJ PRÄS SG3
"frag~en" * V IMP PRÄS SG2
Frage
Wie sehen die entsprechenden STTS-Tags aus?
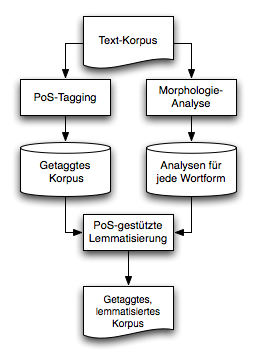
Lösungsansatz: Lemmatisierung mit PoS-Tagging
- Mache PoS-Tagging mit Text-Korpus!
- Extrahiere und lemmatisiere alle Wortformen aus Text-Korpus!
- Suche für jedes Token im Korpus die zu seinem PoS-Tag passenden Analysen!
Lösungsansatz: Lemmatisierung mit PoS-Tagging
Nachteile des obigen Verfahrens
- Prozess-Synchronisierung
: Bevor mit der PoS-gestützten Lemmatisierung begonnen werden kann, müssen alle Wortformen
analysiert sein.
- Speicherbedarf
: Gleichzeitiger Zugriff auf alle morphologischen Analysen aller Wortformen bei der
Lemmatisierung (z.B. ein Hash, welcher als Schlüssel die Wortform hat und als Werte die
Analysen).
- Laufzeit
: Die Entscheidung, ob eine Analyse zum zugewiesenen PoS-Tag passt, muss ausprogrammiert
werden.
Vorteil des obigen Verfahrens
Falls das Morphologieanalysesystem eine grössere lexikalische Abdeckung hat als der Tagger, können
bei der Entscheidung Tagging-Fehler entdeckt und korrigiert werden.
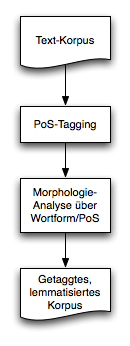
Lösungsansatz: Analyse von getaggten Wortformen
- Das Morphologieanalyse-System bekommt nicht die rohen Wortformen, sondern getaggte
Wortformen als Input und analysiert diese.
- Ein selbstentwickeltes Morphologie-System kann leicht auf dieses Input-Format angepasst
werden (mittels xfst-Operationen innerhalb des FSM-Ansatzes.
Beispiel 11.4.2 (STTS-basierter Analyse-ET von mOLIF).
xfst[1]: apply up rechtslastiger_ADJA
rechtslastig ADJA Pos.Masc.Nom.Sg.St
rechtslastig ADJA Pos.Masc.Nom.Sg.Mix
rechtslastig ADJA Pos.Fem.Dat.Sg.St
rechtslastig ADJA Pos.Fem.Gen.Sg.St
rechtslastig ADJA Pos.*.Gen.Pl.St
xfst[1]: up rechtslastiger_ADJD
rechtslastig ADJD Comp
|
Problem der Mehrdeutigkeit des Lemmas
Mehrdeutigkeit des Lemmas
Beispiel 11.4.3 (GERTWOL-Analysen).
"<*abteilungen>"
"*abt~ei#lunge" S FEM PL NOM
"*ab|teil~ung" S FEM PL NOM
…
"<*ministern>"
"*minister" S MASK PL DAT
"*mini|stern" S MASK SG NOM
…
"<*flugzeuge>"
"*flug|zeug" S NEUTR PL NOM
"*flug#zeug~e" S MASK SG NOM
…
"<*verbrechen>"
"*verb#rechen" S MASK SG NOM
"*verb#rech~en" S NEUTR SG NOM
"*ver|brech~en" S NEUTR PL DAT
…
"<*geldwäschereibestimmung>"
"*geld#wäsch~e#reib~e#stimm~ung" S FEM SG NOM
"*geld#wäsch~er#eib~e#stimm~ung" S FEM SG NOM
"*geld#wäsch~er~ei#be|stimm~ung" S FEM SG NOM
…
"<*arbeitstag>"
"*arbeit\s#tag" S MASK SG NOM
"*arbeit#stag" S NEUTR SG NOM
…
"<bedacht>"
"be|denk~en" V PART PERF
"be|dach~en" V IND PRÄS PL2
"be|dach~en" V PART PERF
"be|dacht" A(PART) POS
…
Problem
Gemäss [VOLK 1999] erhalten etwa 10% aller Nomen und etwa 6% aller Verbformen von modernen
Zeitungskorpora durch GERTWOL mehr als 1 Lemma zugewiesen.
Einfacher Lösungsansatz nach [VOLK 1999]
- Strafpunkte für Komplexität
: Jede Kompositionsgrenze (#) kostet 4 Punkte, schwache Kompositionsgrenze (|) 2 Punkte,
Derivationsgrenze (˜) 1 Punkt.
- Strafpunkte für unwahrscheinliche Morpheme
: Handverlesene konfliktträchtige Morpheme erhalten 100 Strafpunkte (z.B. “stag” oder
“dach˜en”)
Analysen mit ihren Strafpunkten
Beispiel 11.4.4 (GERTWOL-Analysen).
"<*abteilungen>"
"*abt~ei#lunge" S FEM PL NOM 5
"*ab|teil~ung" S FEM PL NOM 3
…
"<*ministern>"
"*minister" S MASK PL DAT 0
"*mini|stern" S MASK SG NOM 2
…
"<*flugzeuge>"
"*flug|zeug" S NEUTR PL NOM 2
"*flug#zeug~e" S MASK SG NOM 5
…
"<*verbrechen>"
"*verb#rechen" S MASK SG NOM 4
"*verb#rech~en" S NEUTR SG NOM 5
"*ver|brech~en" S NEUTR PL DAT 3
"ver|brech~en" * V INF
…
"<*geldwäschereibestimmung>"
"*geld#wäsch~e#reib~e#stimm~ung" S FEM SG NOM
"*geld#wäsch~er#eib~e#stimm~ung" S FEM SG NOM
"*geld#wäsch~er~ei#be|stimm~ung" S FEM SG NOM
…
"<*arbeitstag>"
"*arbeit\s#tag" S MASK SG NOM
"*arbeit#stag" S NEUTR SG NOM
…
"<bedacht>"
"be|denk~en" V PART PERF 3
"be|dach~en" V IND PRÄS PL2 103
"be|dach~en" V PART PERF 103
"be|dacht" A(PART) POS 2
…
Lösungsansatz II: Priorisierung von Lexikoneinträgen
Überanalysen und Lexikalisierung
Keine Überanalyse von Wörtern, welche im Lexikon vorkommen!
Beispiel 11.4.5 (mOLIFde:▸▸▸).
Der Lexikoneintrag “Pomade” unterdrückt die Dekomposition “Po#made”, “Verbraucher” unterdrückt
“Verb#raucher”.
Umsetzung
Die unerwünschten Mehrfachanalysen lassen sich innerhalb des FSM-Ansatzes mit normalen
FSM-Mitteln wie Komposition und Ersetzen erkennen und auch darin eliminieren.