|
|
[ Weiter ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Entstehung
mOLIFde ist als gemeinsame praktische Seminararbeit von Luzius Thöny und Thomas Kappeler unter der Leitung von S. Clematide im Sommersemester 2005 im Seminar "Lexikalische Ressourcen in der CL" entstanden.
Ziel
Im Projekt mOLIFde soll ein umfassendes und lexikographisch leicht erweiterbares System für Morphologieanalyse und -generierung für Deutsch entstehen, welches Flexion, Konversion, Komposition und produktive systematische Derivation beinhaltet.
Status
In den Hauptkategorien Nomen, Verb und Adjektiv ist die Flexion vollständig. Derivation für Verben (Verben mit abtrennbaren Präfixen), Substantive und Adjektive, Komposition nur für Substantive.
Maximale Benützung lexikographischer Standards: ELM-DE und OLIF
Die Anzahl, Art und Anordnung der morphosyntaktischen Merkmale folgt den Spezifikationen des europäischen Lexikonstandards für Deutsch [EAGLES 1996], welcher weitestgehend das grosse STTS-Tagset [SCHILLER et al. 1999] realisiert. Die Kodes für die Flexionsklassen folgen dem Industriestandard OLIF, welcher Bedürfnisse aus Übersetzung und Terminologie abdeckt.
Minimale lexikographische Schnittstelle
Lemma-und-Paradigma-Ansatz
Die minimale Information für die Flexions-Morphologie:
Dies determiniert alle möglichen Wortformen und ihre morphosyntaktischen Eigenschaften vollständig und eindeutig.
Beispiel 8.1.1 (Lexikographische Schnittstelle in mOLIFde).
Hinweis
Die konkrete lexikographische Repräsentation der Lemmata ist dateibasiert. Alle Lemmata einer Flexionsklasse sind in einer eigenen Datei im Zweizeilen-Textformat (double-spaced text format) von xfst abgelegt. Inhalt der Datei lemma/verb/OLIF387Deriv.slex
h a u s | h a l t
a u s | h a l t |
Eine andere lexikographischen Schnittstelle
Beispiel 8.1.2 (Schnittstelle in SMOR [SCHMID et al. 2004]). Lexikoneinträge beinhalten strukturelle (<PREF>), flexionsbezogene (a:i), morphotaktische (<nativ>) und morphologische (<VVPres2t>) Information. Die Paradigmen ergeben sich teilweise aus mehreren Einträgen. Stammänderungen sind immer im Lexikon kodiert.
<Base_Stems>haus<PREF>:<><ge>ha:i<>:elt<V><base><nativ><VVPastStr>
<Base_Stems>haus<PREF>:<><ge>ha:ält<V><base><nativ><VVPres2t> <Base_Stems>haus<PREF>:<><ge>halt<V><base><nativ><VVPP-en> <Base_Stems>haus<PREF>:<><ge>halt<V><base><nativ><VVPres1> <Base_Stems>Roß:s<>:s<>:e<NN><base><nativ><NNeut/Pl> |
Hinweise
<> steht für ε, <…> für Mehrzeichensymbole in dem von SMOR verwendeten SFST-Format (Stuttgart Finite State Tools). : trennt wie in XFST obere und untere Sprache.
OLIF: Ein Industriestandard für lexikalische Ressourcen
Open Lexicon Interchange Format
OLIF ist ein XML-basiertes Austauschformat mit folgenden Eigenschaften:
OLIF-Flexionsklassen für Deutsch
Der OLIF-Standard umfasst eine Teil-Spezifikation für empfohlene Werte der Flexionsklassen
des Deutschen (Values for Recommended Values OLIF Data Categories).
Es sind 702 (unmotiviert durchnummerierte) Klassen , welche (leider) nur durch ein Beispiel und eine minimale Beschreibung bestimmt sind.
Verteilung der Flexionsklassen auf die Hauptwortarten: Adjektive (34), Verben (388), Nomen (216).
Konsequenz der arbiträren Nummerierung
Die morphologischen Eigenschaften der Klassen müssen aus dem Standard teilweise rekonstruiert werden!
Beispiele für Adjektivklassen
Welche Eigenheiten weisen die folgenden Lemmata wohl auf?
klein, sicher, arm, dunkel, bös, leicht, bang, schmal, allg., alt, hoch, nah, wild, gut, weise, teuer, geziert, Schweizer, rosa, groß, scheidend, naß, gesund, kraß
Wer es nicht weiss, kann es online herausfinden: http://www.cl.uzh.ch/siclemat/sprachanalyse/molif/
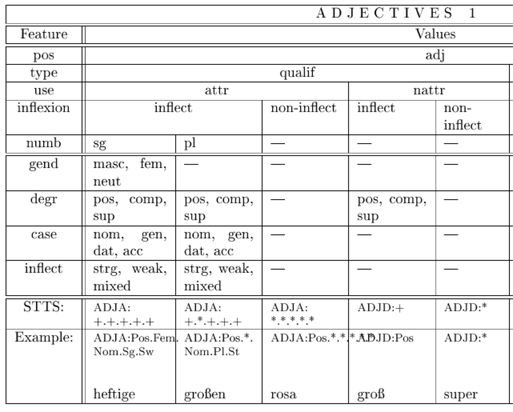
Morphosyntaktische Merkmale in ELM-DE
Legende zu ELM-DE für Adjektive
[ Weiter ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]