Fragen, wie Hebungssätze auch, sind typische Vertreter von Sätzen mit unbeschränkter Abhängigkeit. Fragen erlauben noch viel mehr Varianten von unbeschränkten Abhängigkeiten als Hebungssätze.
Unbeschränkte Abhängigkeit bedeutet, wie wir in der letzten Vorlesung gesehen haben, dass eine Bedingung sich über mehr als eine Regel erstreckt. So muss in Hebungssätzen die Information, ob das Subjekt des untergeordneten Satzes als Subjekt des übergeordneten Satzes (also gehoben) auftritt, über mehrere Regeln weitergegeben werden:
John scheint [zu gehen] (Raised) <==>
Es scheint, [dass John geht] (Non-raised)
S --> NP(RaisInfo), VP(RaisInfo). % Prologvariable RaisInfo NP(raised) --> 'John'. % RaisInfo = raised NP(nonraised) --> 'es'. % RaisInfo = nonraised, dummy es VP(RaisInfo) --> V, S_u(RaisInfo). % S_u untergeordneter Satz S_u(raised) --> VP. S_u(nonraised) --> NP(raised), VP. %In S_u nicht dummy es -> NP(raised)
Obige DCG ist etwas unbefriedigend:
Allgemein gilt für unbeschränkte Unabhängigkeiten: Eine Konstituente, die an ihrer kanonischen Position fehlt, erscheint weiter oben in der Syntaxstruktur, weiter vorne im Satz.
(Frage) Wen1 hat [S-PART Peter t1 gesehen]? (Hebung) John1 scheint [S-INF(GB)/V-INF(LFG/HPSG) t1 zu gehen]. (Topikalisierung) Bananas1, [S-FIN I like t1].
Der Unterschied zwischen Hebungs- bzw. Kontrollsätzen und typischen unbeschränkten Abhängigkeiten (Fragen, Relativsätze, Topikalisierungen) besteht darin, dass bei letzteren lokal wirklich eine syntaktische Lücke vorkommt, also in einem lokalen Baum eine Konstituente fehlt. Bei Hebungssätzen hingegen ist die Lücke bloss semantisch (ganz klar zumindest in LFG und HPSG, wo Hebungsverben nicht wie in GB Sätze, sondern VPs einführen), bei Kontrollsätzen ist gar bloss eine semantische Koindexierung nötig.
Die Information, ob eine Konstituente in der kanonischen Position oder der weiter vorne liegenden Position steht, muss über die ganze Strecke zwischen den beiden Positionen vermittelt werden. Die leerstehende kanonische Position wird als Lücke (Gap), die weiter vorne liegende Position, die die Konstituente enthält, wird als Füller (Filler) bezeichnet. man spricht deshalb auch von Filler-Gap Konstruktionen. In Prolog behandelt man sie allgemein mit dem sog. Lückenfädeln (Gap Threading)
Lückenfädeln ist ein Weg, "die Lückenhafigkeit oder aber Lückenlosigkeit eines eingebetteten Satzes nach aussen zu kommunizieren" (ECL I, Kapitel 5.1.2.1.3).
NP(gap) --> []. % Kommuniziert Lückenhaftigkeit nach aussen. NP(nogap) --> 'John'. % Kommuniziert Lückenlosigkeit nach aussen.
S(GapInfo) --> NP(GapInfo), VP(GapInfo) % allgemeine Satzregel, mit oder ohne NP-Lücke
Die Prologvariable GapInfo enthält und transportiert die Information über Lückenhaftigkeit oder Lückenlosigkeit.
%% Für Hebungssätze S(GapInfo) --> NP(GapInfo), VP(GapInfo). NP(nogap) --> 'John'. NP(gap) --> 'es'. % dummy-es ist auch ein Lücke NP(gap) --> [].
Falls die NP des übergeordneten Satzes keine Lücke ist, so muss die NP des untergeordneten Satzes eine Lücke sein:
VP(nogap) --> V, S(gap). % No Gap in matrix -> gap in sub % John1 scheint [t1 zu gehen]
Und umgekehrt:
VP(gap) --> V, S(nogap). % Gap in matrix -> no gap in sub % (Es)1 scheint, dass John1 geht.
Eine einfache Grammatik für Fragen sieht analog aus:
%% Für Fragen: Wen1 hat [S-PART John t1 gesehen]?, Who1 does [John love t1]? S_top --> S(GapInfo). S(GapInfo) --> NP(GapInfo), VP(GapInfo). NP(nogap) --> 'John'. NP(nogap) --> 'wen'. NP(gap) --> []. VP(nogap) --> V, S(gap). % No Gap in matrix -> gap in sub VP(gap) --> V, S(nogap). % Gap in matrix -> no gap in sub
Die VP-Regeln besagen, dass entweder der übergeordnete oder der untergeordnete Satz eine Lücke enthält.
Auch Relativsätze können so behandelt werden. Die folgende Grammatik behandelt Subjektsrelativsätze:
%% Subjektsrelativsatz: The man1 who[S-GAP t1 likes her]. %% Für Subjektsrelativsätze S_top --> S(nogap). S(GapInfo) --> NP(GapInfo), VP(GapInfo). NP(nogap) --> Det, N, OptRel. NP(gap) --> []. OptRel --> []. % No relative clause OptRel --> RelPron, S(gap).
ECL I Kapitel 5.1.2.1.3 behandelt Relativsatz-Lückenfädeln etwas anders, um auch Objektsrelativsätze zu behandeln. Der Ansatz ist dort nicht sehr elegant, so dass ich ihn hier nicht behandle.
%% Objektsrelativsatz: The man1 who [S-GAP she likes t1].
Subjekts- und Objektsrelativsätze brauchen ein Gap an einem verschiedenen Ort, aber nicht an beiden.
*The man who [S-GAP t1 likes t1].
Die Information über die Lückenhaftigkeit muss also zwischen Subjekt und Objekt geteilt werden
S(GapInfo) --> NP(GapInfo), VP(GapInfo).
Falls der Wert aber einfach weitergereicht wird, so entstehen Gaps an allen Positionen!
%% Falsche VP-Regel für obiges S, produziert zwei Gaps %% VP(GapInfo) --> V NP(GapInfo). %% *The man who [S-GAP t1 likes t1].
Man könnte also fordern, wie in den obigen Grammatiken für Fragen und Hebung:
%% Schon besser: VP(nogap) --> V, NP(gap). % No Gap in Subj -> gap in Obj VP(gap) --> V, NP(nogap). % Gap in Subj -> no gap in Obj
Aber das erlaubt völlig falsche Hauptsätze!
*[NP-NOGAP The man] [VP-NOGAP likes [NP-GAP]].
Also: Die Gapwerte in
S(GapInfo) --> NP(GapInfo), VP(GapInfo).
müssen miteinander kommunizieren, aber sie dürfen weder einfach identisch noch einfach entgegengesetzt sein.
Vielmehr:
Falls das Subjekt schon eine Lücke ist, so erhält es zwar den Wert (gap), muss aber den Wert (nogap) an die VP, die das Objekt enthält, ausgeben. Das lässt sich nur durch die Vergabe von zwei Gapwerten, einem Eingabewert (der Forderung ans Subjekt) und einem Ausgabewert verwirklichen. Der Ausgabewert wird dabei zum Eingabewert (Forderung) für die VP und damit das Objekt
S(GapInfo) --> NP(GapInfo,NewGapInfo), VP(NewGapInfo). %%oder S(GapIn) --> NP(GapIn,GapOut), VP(GapOut). %% Variablenwerte falls der Satz eine Lücke verlangt, die das Subjekt ist: S(gap) --> NP(gap,nogap), VP(nogap).
Damit der (untergeordnete) Satz S(gap) weiss, ob die von ihm geforderte Lücke auch tatsächlich auch erscheint, ist es sinnvoll, dem Objekt und damit der VP einen Ausgabewert zu geben und diesen an den Satz zurückzuliefern:
S(GapBegin,GapEnd) --> NP(GapBegin,GapMid), VP(GapMid,GapEnd).
Mit dieser Methode lassen sich Gaps auch über komplex geschachtelte Sätze hinweg richtig behandeln. Diese Methode ist nichts anderes als eine Neuauflage der berüchtigten Prolog-Differenzlisten:
s(Beginning, End) :- np(Beginning, Mid), vp(Mid, End). %% äquivalent zu s --> np, vp.
Die obigen Beispielgrammtiken sind noch etwas unbefriedigend, da sie die Verbformen nicht behandeln.
Es scheint, dass [John geht]. *Es scheint, dass [John zu gehen]. *John1 scheint, dass [t1 geht]. John scheint [t1 zu gehen].
Wir können unsere Grammatik für Hebungssätze leicht erweitern:
%% Für Hebungssätze S_top --> S(fin,GapInfo). S(Vform,GapInfo) --> NP(GapInfo), VP(Vform,GapInfo). NP(nogap) --> 'John'. NP(gap) --> 'es'. NP(gap) --> []. VP(Vform,nogap) --> V(Vform), S(inf,gap). % No Gap in matrix -> gap in sub VP(Vform,gap) --> V(Vform), Compl, S(fin,nogap). % Gap in matrix -> no gap in sub Compl --> 'dass'.
Der Hauptsatz fordert ein finites Verb. Diese Forderung wird weitergegeben und erfüllt.
VP(Vform,nogap) --> V(Vform), S(inf,gap). % No Gap in matrix -> gap in sub
In der gleichen PS-Regel wird für den untergeordneten Satz zutreffend eine infinite Verbform gefordert. Die Werte für V(Vform) und S(Vform) in dieser Regel dürfen nicht geteilt werden.
Die Forderung nach der Verbform im untergeordneten Satz ist aber vom Verb abhängig. Das folgende Grammatiksegment lizenziert eine NP-Lücke für das englische Kontrollverb want:
VP(OldVform,nogap) --> V(Vform,GapInfo), S(Vform,GapInfo). V(inf,gap) --> 'wants'. S(Vform,GapInfo) --> NP(GapInfo),VP(Vform,GapInfo). NP(gap) --> [].
Hier werden die Werte für V(Vform) und S(Vform) geteilt, was dem unter- und übergeordneten Satz dieselbe Verbform bescheren würde! In anderen Worten: Ein Verb muss sowohl Verbformforderungen erhalten (Eingabe), als auch stellen können (Ausgabe):
VP(Vform,Vform1,nogap) --> V(Vform,Vform0,GapInfo), S(Vform0,Vform1,GapInfo). V(fin,inf,gap) --> 'wants'. V(inf,inf,gap) --> 'want'. S(Vform,Vform0,GapInfo)--> NP(GapInfo),VP(Vform,Vform0,GapInfo). NP(gap) --> [].
In GB werden Konstituenten von der kanonischen Position in der D-Struktur in die eine unbeschränkte Abhängigkeit involvierende S-Struktur bewegt. Anders als in anderen Zugängen ist Bewegung hier nicht nur als Metapher zu verstehen. Wir haben in vorhergehenden Vorlesungen, insbesondere Vorlesungen 4 und 5, die Grundlagen der Transformation besprochen.
In HPSG und LFG ist Bewegung nur als eine Metapher aufzufassen; beide Ansätze sind monostratal, kennen also nur eine syntaktische Strukturebene. Generell gesagt werden kanonische und nichtkanonische Positionen (in denen die 'bewegte' Konstituente steht) in HPSG durch Koreferenz (structure-sharing) verbunden (notiert z.B. [1]) Auch wenn HPSG keine PS-Regeln kennt, so haben wir gesehen, dass das Zusammenwirken
zu PSG äquivalente Regeln aufstellt, für die Specifier -Regel beispielsweise
X" --> X'[SPR:<[1]>], [1].
Der Einfachkeit halber kann man deshalb auch HPSG-Regeln als PSG ausdrücken.
Für Lücken verwendet man in HPSG das SLASH Merkmal. Eine VP, der eine Objekts-NP fehlt, (z.B. Wen1 hat [er gesehen t1]) hat eine ungesättigte Valenz auf der COMPS Subkategorisierungsliste, und sieht in einfachster Notation (wie sie Borsley verwendet, siehe die Bemerkungen zu Borsley aus der letzten Vorlesung) so aus:
V"[SLASH:NP]
was äquivalent ist zu
- -
|HEAD verb |
| - - |
| | - -| |
|COMPS <|HEAD |[1]noun ||>|
| | - -| |
| - - |
|SLASH [1] |
- -
Das Merkmal SLASH erhielt seinen Namen aus der Kategorialgrammatik, da dort ungesättigte Valenzen durch einen Trennungsstrich (engl. slash) dargestellt werden. V/N in Kategorialgrammatik entspricht also (etwa) V"[SLASH:NP].
Das SLASH Merkmal wird in jedem Fall mit der Mutter geteilt und so hochgereicht:
%% Bananas1, [I like t1].
S[SLASH:NP]
 NP VP[SLASH:NP]
I
V NP[SLASH:NP]
like |
[]
%% The girl1 who [Stephan saw t1] eats.
S[SLASH:NP]
NP VP[SLASH:NP]
Stephan
V NP[SLASH:NP]
saw |
[]
NP VP[SLASH:NP]
I
V NP[SLASH:NP]
like |
[]
%% The girl1 who [Stephan saw t1] eats.
S[SLASH:NP]
NP VP[SLASH:NP]
Stephan
V NP[SLASH:NP]
saw |
[]
Die oberste Konstituente eines Satzes darf aber keine SLASH Merkmale mehr enthalten. Bis zur obersten Satzebene müssen auch 'verspätete Valenzen' gesättigt sein. Die PSG-Regel, die eine ungesättigte Valenz mithilfe des SLASH-Merkmals erlaubt, sieht so aus:
S --> [1], S[SLASH: [1]].
%% [Bananas1, [I like t1]]. (Topikalisierung)
S
NP[1] S[SLASH:[1]]
Bananas
NP VP[SLASH:[1]]
I
V NP[SLASH:[1]]
like |
[1]
Die NP-Regel lizenziert das Fehlen ihrer eigenen Wiederholung in einem Relativsatz:
NP[1] --> DET, N, OptRel[SLASH:[1]].
%% [The girl1 who [Stephan saw t1]eats]. (Relativsatz)
S
NP[1] VP
 eats
DET N OptRel[SLASH:[1]]
the girl
eats
DET N OptRel[SLASH:[1]]
the girl  PRO S[SLASH:[1]]
who
NP VP[SLASH:[1]]
Stephan
V NP[SLASH:[1]]
saw |
[1]
PRO S[SLASH:[1]]
who
NP VP[SLASH:[1]]
Stephan
V NP[SLASH:[1]]
saw |
[1]
In Hebungs- und Kontrollsätzen, wie wir in der letzten Vorlesung gesehen haben, können die unbeschränkten Abhängigkeiten ohne das SLASH Merkmal erklärt werden, und werden also anders verarbeitet als typische unbeschränkte Abhängigkeiten, in denen wirklich eine lokale syntaktische Lücke vorliegt.
Die Verbstellungsvariationen zwischen Aussage- und Fragesätzen werden in HPSG meist dadurch behandelt, dass eine ID/LP-Grammatik, in der die Konstituentenreihenfolge innerhalb einer Regel separat spezifiziert wird, zum EInsatz kommt.
Wie in HPSG ist in LFG Bewegung nur als eine Metapher aufzufassen; beide Ansätze sind monostratal, kennen also nur eine syntaktische Strukturebene. Generell gesagt werden kanonische und nichtkanonische Positionen (in denen die 'bewegte' Konstituente steht) in LFG durch Annotationen der PS-Regeln verbunden, welche die f-Struktur aufbauen.
Wir haben in der letzten Vorlesung gesehen, wie LFG Hebung- und Kontrollsätze behandelt. Wie in HPSG werden typische unbeschränkte Abhängigkeiten, wie sie in Fragen, Relativsätzen oder Topikalisierungen vorkommen, etwas anders behandelt. Für Topikalisierungen wird beispielsweise eine dem Hauptsatz übergeordnete Konstituente angenommen, die eine beliebige (XP) topikalisierte Konstituente aufnehmen kann (vereinfacht, siehe [Sells 1985: 179 ff]):
S' --> XP S
^TOPIC=v ^=v
Für den Satz "Maria1, Max loves t1" ergibt das folgende f-Struktur:
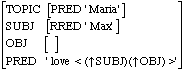
Das LFG Kohärenzprinzip, welches sicherstellt, dass alle f-Strukuren wohlgeformt sind, wird um die Forderung erweitert, dass das TOPIC Merkmal stets mit einem anderen verbunden sein müsse - in diesem Fall natürlich dem Objekt OBJ.
Dieselbe Topikalisierungsregel kann natürlich auch für wh-Fragen Anwendung finden. Dabei erscheint das Fragepronomen in der TOPIC-Position und hinterlässt an der kanonischen Stelle eine Lücke. Die deutsche f-Struktur für "Wer liebt Maria ?":

Die Verbstellungsvariationen zwischen Aussage- und Fragesätzen sind aber mit dieser Topikalisierungsregel noch nicht gelöst. Dazu muss