International Semantic Web Working Symposium
SWWS
sponsored by the
National Science Foundation, Information and Data Management
Program
Stanford University, California, USA
July 30 - August 1, 2001
Report
Integration, Interoperation and Composition Track
Vipul Kashyap
Applied Research, Telcordia Technologies
kashyap@research.telcordia.com
Abstract
This is a report on the proceedings of the track on Integration, Interoperation
and Composition as a part of the 1st International Semantic Web Working Symposium, held in Stanford from July 30
- August 1, 2001. The track description and organization is first discussed. Then we present a brief discussion
on the issues discussed and the missing gaps identified for enabling the Semantic Web. Next we shall discuss the
research agenda and identify the priorities for academia and industry.
Track Description and Organization
Interoperation and Integration can be defined by broadening the current definitions
used in the federated database literature. Interoperation may be defined as a loose coupling across information
sources, semantic metadata descriptions and ontologies. Typically an external agent or system is responsible for
decomposition of an information request and mapping the decomposed pieces onto the given targets. Integration on
the other hand refers to a tight coupling and suggests that the given information sources, semantic metadata descriptions
are somehow coalesced together and can be queried as a single unit. Composition on the other hand refers to the
act of combining pieces of information at a level granularity smaller than that involved in integration and interoperation.
Examples of pieces are: constraints, policies, vocabularies and language transformations. An interesting case of
composition is when you may want to compose proofs of correctness to prove higher level security and transaction
policies.
Based on the above definition the track was (approximately) divided into four
broad sessions involving 12 presentations.
Issues
The central observation of all the speakers presenting in the track can be
summed up as: It is crucial for the interoperability layer to migrate
from the syntactic to the semantic!
Semantic Interoperability (in the general sense including integration and composition) could be implemented at
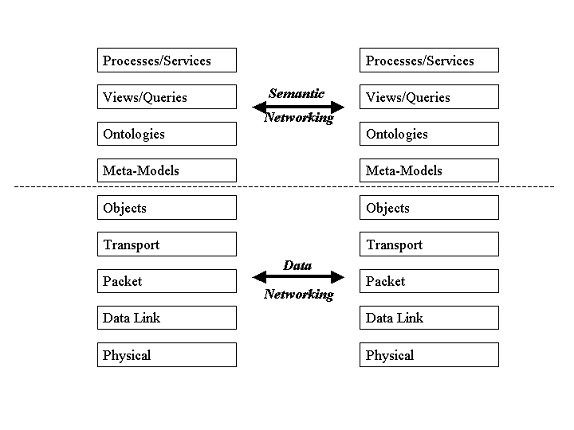
different levels, and there were proposals to organize them approaches in a layered manner. This is illustrated
in the figure below and seeks to differentiate between data networking and "semantic" networking.
Building on the success of the data networking and middleware communities, the above picture tries to relate organize
and relate the semantic web efforts along multiple layers, some of whom are described below:
The ability to organize semantic web research along these layers helps us organize
the work require to build out the underlying infrastructure of the semantic web. The issues that arise are: development
of standards and industry wide APIs at each of the layers. Building up semantic-web specific functions such as
semantic routings, "semantic" content delivery networks. Specification of further application layers
may also be required.
One of the most important topics on which semantic interoperability depends is the problem of ontology interoperation,
which was discussed by a large number of speakers. Some topic that were discussed were: integration between RDF,
Frame based and Object Oriented data (meta-model reconciliation), merging and exchange of data between different
RDF models, and the ability to specify mappings across terms in different ontologies. Some of the issues that were
discussed in the context of the latter topic were the reconciliation of various types of heterogeneities and techniques
for specifying articulation rules and correspondence across ontologies.
Languages for representation of ontology transformations/mappings and for "semantic" web programming
were also discussed. Approaches to represent computations in RDF were presented and their similarity to the notion
of web services was noted. Representations of active/re-active rules and action using RDF, and integration of RDF/DAML+OIL
with a programming language were two diverse approaches discussed. An interesting paper on proving properties of
transformations based on composition of the transformations (and their corresponding proofs) was also presented.
Some interesting presentations dealt with the issue of semantic web in the presence of multimedia data. The MPEG-7
standard was discussed and the need to specify the semantics of the MPEG-7 metadata was recognized. The ability
to compose semantics of document components in the presence of spatio-temporal constraints was identified as a
crucial requirement for multimedia semantics. The need to link and interoperate with ontologies from other domains
was also recognized. Digital Rights Management was especially an important topic from the perspective of multimedia
data and there were discussions related to rigorous specification and enforcement of digital rights associated
with a multimedia document. There was a suggestion from a participant that ongoing and previous work in digital
libraries should be leveraged for the semantic web.
Missing Gaps
Whereas there were a lot of issues relating to the Semantic Web covered by
the speakers in the track some critical problems that need to be addressed had not been covered. Some of the problems
that comprise the missing gap are:
Research Agenda
The research agenda for the Semantic Web can be divided along the following lines.
Industry research typically needs to focus on shorter term, applied research with emphasis on proof of concept
prototypes that can be productized if there is commercial potential. Academia perform longer term fundamental research,
since they don't face commercial or business pressures. We now try to outline the research agenda for industry
and the academia in the context of the semantic web.
Some research priorities for the industry are as follows:
Some research priorities for academia and long-term projects undertaken by some industrial R&D Labs are as
follows:
Industry and academia both seek funding from Government agencies such as DARPA,
NSF, etc. Industry in particular seeks funding for long-term projects that do not have immediate commercial viability.
It is a moot point whether the semantic web will be the next "internet" to be funded by DARPA. Government
funding may turn out to be an exciting way to promote industry academia collaboration, as seen in the CoAx project
by Allsopp, et. al.
Conclusion
In conclusion, the Interoperability, Integration and Composition track had
an interesting collection of papers, but crucial problems important for the enabling of the semantic web were either
missing or not dealt with. Some open difficult problems were alluded to but not explicitly dealt with. In general,
the track had a very strong academic flavor and attempts should be made to involve the industry in a more significant
manner.
.