Restricted information
WebExtrAns
WebExtrAns was a privately funded
project that run from Nov. 1999 to Dec. 2002.
Like ExtrAns, WebExtrAns was intended to test how far it is
possible to go
in the world of Answer Extraction. As the name suggests, Answer Extraction
(AE) techniques attempt to extract the answers to the user query in a set of
documents. AE is not question answering because it does not try to
generate the answer from scratch. In other words, if a specific sentence in
the documents directly answers a query, it is retrieved. But if the answer is
not explicitly expressed in the document, an AE system will not try to infer
it. AE is a specific type of information retrieval.
The domain of application of AE includes:
- Interfaces to machine-readable technical manuals.
- On-line help systems for complex software.
- Help desk systems in large organisations.
- Public inquiry systems over the Internet.
In all of these applications it is important to find all the
answers to the question (high recall), since technical manuals generally
explain things only once. It is important to find only the answers,
without garbage (high precision), since the user is interested in getting an
answer quickly. Achieving high recall and precision in small retrieved data
(only sentences or part of sentences) will require a degree of natural
language processing. ExtrAns and WebExtrAns aim at testing if it is possible
to use current NLP technologies in AE over technical manuals.
By NLP technologies we mean, among others:
- Full parsing of the sentences.
- Disambiguation.
- Anaphora resolution.
- Construction of a Minimal Logical Form (MLF).
The data to use is a technical manual of a commercial aircraft, the AIRBUS
320, made available by SR Technics, a
subsidiary within the SAirGroup (formerly Swissair group). This manual has the
following characteristics:
- The size is over 100 Mb, far larger than ExtrAns'manpages.
- The format is SGML.
This allows us to use SGML/XML tools and build a
system that is more portable than ExtrAns.
- The English used in the data is defined by AECMA' Simplified English
(SE). The use of documents in SE simplifies some problems related with
NLP, such as lexical and syntactic ambiguity, anaphora resolution,
ellipsis, and tense. But the hard problems are still there in practically
the same degree: presuppositions, quantification, aspect, lexical
semantics, etc.
WebExtrAns was a joint project between the University of Zurich (Switzerland) and the
University of Tartu (Estonia) and was privately funded.
Example of Interaction with the system
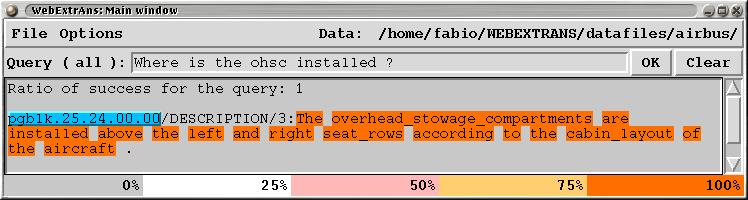
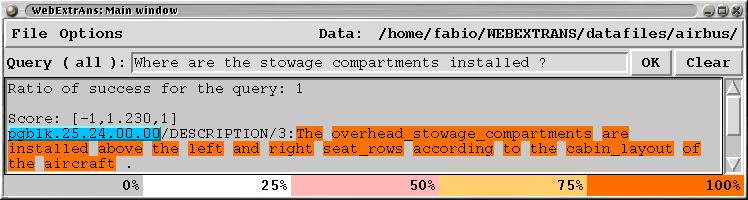
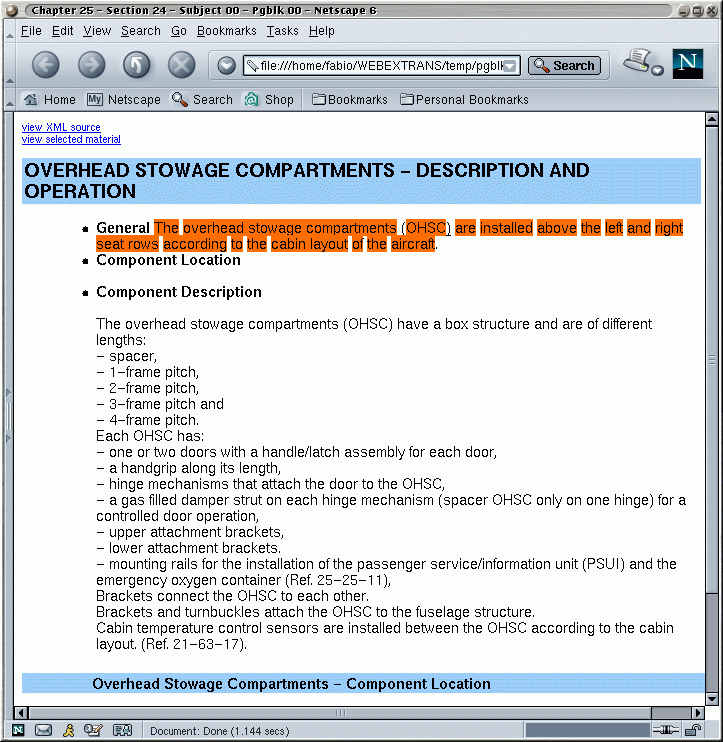
Terminology
One of the main obstacles in processing technical manuals is the high amount
of domain specific terminology. In the course of the projects we experimented
with different tools for terminology extraction. We developed our own tools
for structuring the terminology by synonymy and hyperonymy, helped by our
own visualization tools.
Project results
The collapse of
Swissair
deprived us of our potential partner for a commercial
exploitation of the results obtained in the project.
Besides we could not perform a direct evaluation of usability
with the target users of the system (Aircraft Maintenance
Technicians).
However the project delivered interesting scientific
results, as witnessed from the list of publications (see below).
Although the original focus of the project was on the
Answer Extraction problem, the nature of the documents
to be analyzed (Aircraft Maintenance Manuals) brought us
into the area of Terminology. We had to explore various
Terminology Extraction techniques and find ways to exploit
the extracted terminology within our NLP system.
A working prototype which shows the effectiveness of our
Answer Extraction approach is internally available. Unfortunately
it cannot
be made available on the web because of unsolved copyright
issues regarding the analyzed documents. However an earlier
prototype targeted to a different domain can be accessed
here.
We could summarize the main scientific results of our work
as follows:
- Terminology plays a central role in the processing of
Technical Manuals
- The complexity of parsing technical manuals can be
ascribed to a large part (46% in our case) to terminology.
- Terminological Variants needs to be taken into account, as
effective standardization is still not completely achieved
- Even if complete standardization was achieved within the
manuals, the user of a query system could come up with a novel
variant
- We implemented a prototype showing effective ways to deal
with existing and novel variants
Researchers
University of
Zurich
|
University of
Tartu
|
Publications originated from the Project
- [Rinaldi et al. 2004a]
-
Fabio Rinaldi, Michael Hess, James Dowdall, Diego Mollá, Rolf Schwitter. Question Answering in Terminology-rich Technical Domains,
"New Directions in Question Answering", Maybury, M. T. editor. 2004. AAAI/MIT Press.
- [Schwitter et al. 2004a]
-
Rolf Schwitter, Fabio Rinaldi, Simon Clematide.
The Importance of How-Questions in Technical Domains.
Question-Answering workshop of TALN 04, Fez, Morocco, 22nd April 2004.
- [Mollá et al. 2003b]
- Diego Mollá, Fabio Rinaldi, Rolf Schwitter, James Dowdall, Michael Hess. Answer Extraction from Technical Texts.
IEEE Intelligent Systems, 18(4):12-17, July/August 2003.
- [Mollá et al. 2003a]
- Diego Mollá, Rolf Schwitter, Fabio Rinaldi, James Dowdall, Michael Hess.
NLP for Answer Extraction in Technical Domains. Accepted for publication at the
EACL 03 Workshop: Natural Language Processing for Question Answering, Budapest.
- [Rinaldi et al. 2003b]
- Fabio Rinaldi, James Dowdall, Michael Hess,
Kaarel Kaljurand, Magnus Karlsson. The role of technical
Terminology in Question Answering.
TIA 2003, Terminologie et Intelligence Artificielle,
Strasbourg.

- [Rinaldi et al. 2003a]
- Fabio Rinaldi, James Dowdall, Kaarel Kaljurand,
Michael Hess and Diego Molla.
Exploiting Paraphrases in a Question Answering System.
ACL-2003,
Second International Workshop on Paraphrasing: Paraphrase Acquisition and Applications, pp.25-32. July 11th, Sapporo, Japan.
- [Rinaldi et al. 2002c]
- Fabio Rinaldi, James Dowdall, Michael Hess, Kaarel Kaljurand,
Mare Koitand Neeme Kahusk: Terminology as Knowledge in Answer Extraction.
TKE-2002: 6th International Conference on Terminology and Knowledge
Engineering, 28th-30th August 2002
Nancy, France
- [Rinaldi et al. 2002b]
- Fabio Rinaldi, James Dowdall, Michael Hess, Diego Molla and
Rolf Schwitter: Towards Answer Extraction: An application to Technical Domains.
ECAI-2002, Lyon, 21-26 July, 2002.
In: F. van Harmelen (ed.), ECAI 2002. Proceedings of the 15th European
Conference on Artificial Intelligence, IOS Press, Amsterdam, 2002.
- [Rinaldi et al. 2002a]
- Fabio Rinaldi, Michael Hess, Diego Molla,
Rolf Schwitter, James Dowdall, Gerold Schneider,
and Rachel Fournier: Answer Extraction in Technical Domains.
CICLing-2002, Mexico City, 17-23 February, 2002.
Available from Springer Verlag:
Computational Linguistics and Intelligent Text
Processing. Lecture Notes in Computer Science. VOL. 2276., pg. 360-369.
- [Hess et al. 2002]
- Michael Hess, James Dowdall, Fabio Rinaldi:
The Challenge of Technical Text.
LREC-2002, Workshop on
Question Answering: Strategy and Resources,
Las Palmas, 28 May 2002.
- [Dowdall et al. 2002]
- James Dowdall, Michael Hess, Neeme Kahusk, Kaarel Kaljurand, Mare Koit,
Fabio Rinaldi and Kadri Vider: Technical Terminology as a Critical
Resource. LREC-2002, Las Palmas, 29-31 May 2002.
- [Höfler 2002]
- Stefan Höfler, Link2Tree: A Dependency-Constituency Converter.
Lizentiatsarbeit der Philosophischen Fakultät der
Universtität Zürich, April 2002.
Restricted information
Fabio Rinaldi (rinaldi@ifi.unizh.ch). Last update:
![[CL group]](http://www.ifi.unizh.ch/groups/CL/CLsmallLogo.gif)
{kind=link}