Morphologieanalyse und Lexikonaufbau (6. Vorlesung)
Dozent: Martin VolkToken: (nach [Bußmann 83]: einzelne sprachliche Äusserung)
in einem Text vorkommende Wortformen
Bsp.: "Die Frau jagt die Katze." enthält 5 Token (oder 6 Token, wenn man den Satzendepunkt eigens zählt)
Type: (nach Bußmann: die den sprachlichen Äusserungen zugrundeliegenden abstrakten Einheiten)
in einem Text vorkommende unterschiedliche Wortformen
Bsp.: "Die Frau sah das Mädchen, aber das Mädchen hat sie nicht gesehen." enthält 10 Types ('das' und 'Mädchen' werden nur einmal gezählt; oder 12 Types, wenn man die Satzzeichen eigens zählt; 'sah' und 'gesehen' können auch als zwei Instanzen des selben Lemma-Types gesehen werden.)
> Auf 13.000 Token (=Kap. 3 des Buches) kommen 2427 Types (T/T= 5,35).
> Auf 48.000 Token kommen 3700 Types (T/T= 12,97).
> Auf 1 Mio Token kommen ca. 50.000 Types (T/T = 20)
> Auf 2.5 Mio Token kommen 166.484 Types (T/T= 15,01)
> Type/Token Verhältnis ist niedriger in gesprochener Sprache als in geschriebener Sprache
nur die häufigsten Types werden für die Lexikonerstellung berücksichtigt.
> ungefähr gleich
"Das Verhältnis der Häufigkeit des Auftretens eines Tokens ist invers proportional zu seiner Position in der Häufigkeitsliste."
frequency * rank = constant
Bsp.: (für Englisch; aus Crystal S.87)
| rank | * | frequency | constant |
| 35 | very | 836 | 29.260 |
| 45 | see | 674 | 30.330 |
| 55 | which | 563 | 30.965 |
| 65 | get | 469 | 30.485 |
| 75 | out | 422 | 31.650 |
Problem: Gesetzmässigkeit stimmt nicht ganz am Anfang und am Ende der Liste.
Anmerk.: Anderes Ergebnis von Zipf: Die Häufigkeit des Auftretens eines Wortes ist umgekehrt proportional zu seiner Länge.
nach Meier, H.: Deutsche Sprachstatistik. Hildesheim: Georg Olms. 1964
1 die 349.553 2 der 342.522 3 und 320.072 1. Konjunktion 4 in 188.078 1. Präposition 5 zu 172.625 6 den 138.664 7 das 124.232 8 nicht 114.518 1. Adverb 9 von 113.201 10 sie 102.212 1. Personalpronomen 11 ist 96.970 1. Hilfsverb 12 des 96.190 13 sich 92.945 14 mit 91.552 15 dem 89.109 90 Zeit 14.529 1. Substantiv 127 machen 8.929 1. Vollverb
Vgl. Liste für das Englische und für das Französische (s. Alexejew et al. "Sprachstatistik", Fink, 1973 S. 218 u. S.223-224).
> 1 Mio Token (ca. 50.000 Types), davon machen 6 Types (the, of, and, to, a, in) 205.961 Token aus
die Spitzenreiter in der Häufigkeit sind unterschiedlich für geschriebene und gesprochene Sprache (in gesprochener Sprache häufiger als in geschriebener ist z.B. 'I ')
Beobachtung: Die häufigsten Wörter sind Funktionswörter, vor allem Determiner und Präpositionen. Sie haben normalerweise keine Synonyme und sind syntaxspezifisch.
Allgemein: Die Zuweisung eines 'Tags' (Markierungssymbol) an eine Texteinheit.
Meist: Die Zuweisung eines eindeutigen Wortartsymbols an eine Wortform im Kontext.
Tagging folgt meist auf die morphologische Analyse oder ist selbst lexikonbasiert. Es kann entweder statistisch oder regelbasiert ablaufen. Beispiel:
Morphologische Analyse: Tagger: Junge [Adj, N] Adj Männer [N] N gehen [finV, infV] finV zu [Präp, Adv, iKonj, Adj] Präp ihr. [Pron, Det] Pron
nach Smith (S.86): 5% der Types sind ambig. Da diese jedoch sehr häufig sind, entspricht das bis zu 20% der Token.
nach Charniak (S.49): Im Brown-Corpus sind 11% der Types ambig. Das entspricht jedoch 40% der Token.
Das Tag-Set umfasst die Menge der Tags, die von einem Tagger vergeben werden.
| Tag-Set | Number of Tags |
| Brown Corpus | 87 |
| Lancaster-Oslo/Bergen | 135 |
| Lancaster UCREL | 165 |
| London-Lund Corpus of Spoken English | 197 |
| Penn Treebank | 36 + 12 |
Basiert auf dem LOB (Lancester-Oslo-Bergen) Tag-Set. Dieses enthält rund 120 Tags für die Wortarten plus Tags für die Satzzeichen.
Ausgangstext:
You can drink from a can of beer and fly home like a fly. You live your lives as a man would do time and again. Do you think that a buffalo can buffalo a buffalo?
Der analysierte Text:
You/PPSS can/MD drink/VB from/IN a/AT can/NN of/IN beer/NN and/CC fly/NN home/NN like/CS a/AT fly/NN ./SENT You/PPSS live/VB your/PP$ lives/NNS as/RBC a/AT man/NN would/MD do/DO time/NN and/CC again/RB ./SENT Do/DO you/PPSS think/VB that/CS a/AT buffalo/NN can/MD buffalo/VB a/AT buffalo/NN ?/SENT
Der Xerox-Tagger kann über das WWW getestet werden: http://www.rxrc.xerox.com/research/mltt/Tools/pos.html. Er arbeitet für DE, FR, NL, EN, ES, PT und IT.
(nach [Cutting et al. 92] S.133)
Annahme: die Wahrscheinlichkeit der Aufeinanderfolge von Wortarten ist unterschiedlich. Ausgangspunkt ist einmal die Wahrscheinlichkeit, dass ein gegebenes Wort mit Wahrscheinlichkeit P die Wortart POS1 hat. Die Wahrscheinlichkeit der Wortartenübergänge werden dann berechnet (z.B. indem man manuell disambiguiert ODER abwechselnd manuell disambiguiert, tagged und korrigiert) und über mehrere Wörter hinweg (Tri-Tupel, Quad-Tupel) die maximale Wahrscheinlichkeit der Übergänge ermittelt.
Grundlage: Hidden Markov Modelle (HMM)
Ein Beispiel aus: [Feldweg 96]. Zu taggen sei die Nominalphrase die auf der Bank sitzende Frau. Dort bestehen folgende Mehrdeutigkeiten:
| (.) | die | auf | der | Bank | sitzende | Frau |
| (.) | REL ART DEM | PRP VZS | REL ART DEM | SUB | ADJ | SUB |
Man ordnet den Übergängen zwischen den Wortarten Wahrscheinlichkeiten zu.
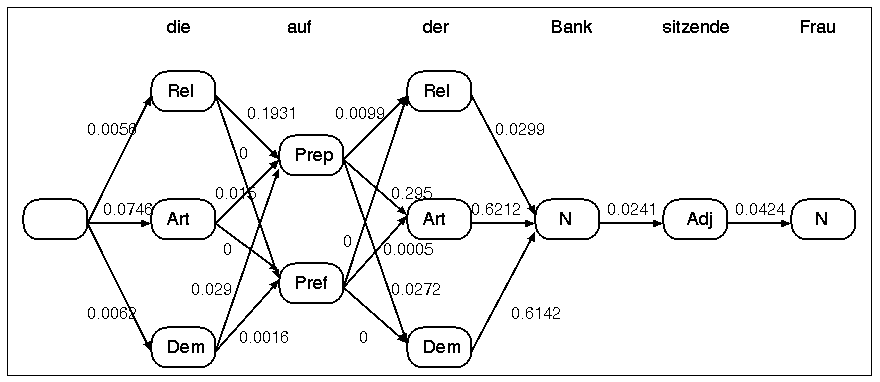
Schliesslich kann jeder Wortform-Wortart-Kombination eine Wahrscheinlichkeit zugeordnet werden:
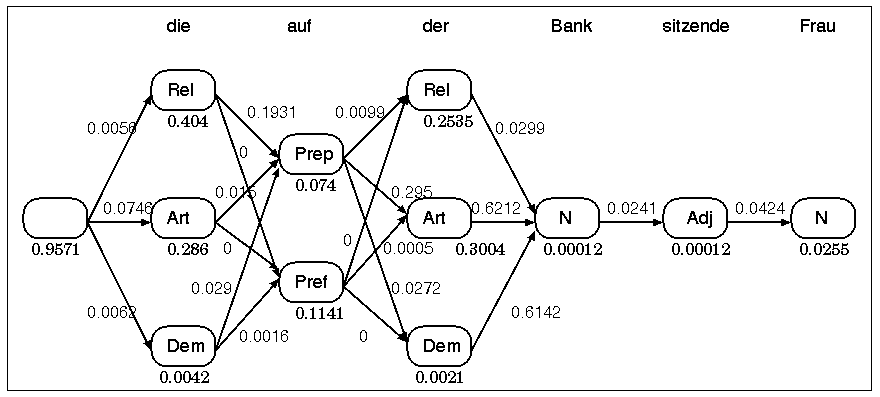
Für jeden möglichen Pfad durch ein solches Netz lässt sich durch Multiplikation der auf dem Pfad liegenden Werte eine Gesamtwahrscheinlichkeit berechnen.
Formal betrachtet handelt es sich bei diesem Verfahren um ein Hidden-Markov-Modell erster Ordnung. Ein solches Modell ist definiert über:
In unserem Beispiel bildet das Vokabular (= die Menge der Wortformen) die Menge V.
Diese Menge entspricht den möglichen Wortarten.
Hier die Übergangswahrscheinlichkeiten zwischen Wortarten.
Dies entspricht der Menge der lexikalischen Wahrscheinlichkeiten: gegeben die Wortart s, wie hoch ist die Wahrscheinlichkeit von Wortform w?
Beim beschriebenen Modell handelt es sich um ein Hidden-Markov-Modell erster Ordnung. Übergangswahrscheinlichkeiten werden dabei nur für direkt benachbarte Zustände berücksichtigt (Bigram-Modell). Es sind jedoch auch Modelle höherer Ordnung möglich.
Das Tagging mittels HMM ist prinzipiell sprachunabhängig. Voraussetzung ist jedoch, dass die in den Gleichungen 1-4 aufgeführten Parameter bekannt sind. Die Gewinnung der Parameter ist jedoch das eigentliche Problem.
Einfach: Bestimmung des Vokabulars
Schwieriger: Festlegung des Tag-Sets (Wortartenmenge und -abgrenzung)
Sehr komplex: Gewinnung von Übergangswahrscheinlichkeiten und Observationswahrscheinlichkeiten. Präzise Werte kennt man nicht. Diese Parameter müssen geschätzt werden (z.B. über bereits getaggte Korpora).
Probleme:
(nach [Church 93] S.7)
Statistische Tagger erreichen eine Genauigkeit von rund 94-97% bei einem Tag-Set wie dem STTS mit rund 50 Tags. Besonderes Handicap für Tagger sind:
... weil wir diese Probleme schon kennen/VVFIN. Wir sollten diese Probleme schon kennen/VVINF. Die Frauen, die/ART Kinder und alte Männer wurden evakuiert. Die Frauen, die/PRELS Kinder und alte Männer evakuierten, wurden geehrt.
Vorsicht! Wenn wir annehmen, dass Sätze im Durchschnitt 20 Wörter lang sind, dann bedeutet eine Fehlerrate von 4%, dass 56% aller Sätze (also jeder zweite Satz) ein falsch getaggtes Wort enthalten. Wenn wir eine Fehlerrate von 4% bei den Sätzen erreichen möchten, dann müsste die Fehlerrate bei den Wörtern auf 0,2% sinken.
Ein frei verfügbarer Tagger für das Deutsche, der mit statistischen Methoden arbeitet, findet sich im Morphy-System der Universität Paderborn. Dieser Tagger läuft unter MS-DOS und Windows95 auf PCs.
Ein weiterer verfügbarer Tagger für das Deutsche wurde an der Universität Stuttgart entwickelt. Er nennt sich TreeTagger und läuft unter SunOS und Linux.