Programmierprojekt "Extraktion aus NEGRA-annotierten Sätzen"
BearbeiterIn: N.N.
Betreuer: Simon Clematide
Einführung
Der klassische Syntaxbaum lässt sich redundanzfrei durch die Relation der unmittelbaren Dominanz zweier Knoten und unmittelbaren linearen Präzedenz von Geschwisterknoten repräsentieren.
Das NEGRA-Annotationsformat enthält zusätzlich noch eine funktionale Bestimmung (syntaktische Funktionen) für jede unmittelbare Dominanzbeziehung. Wortarten können (entgegen der naiven Interpretation der graphischen Darstellung) als Phrasen aufgefasst werden. Den Wortartenphrasen zugeordnet ist jeweils die Wortinformation (Wortform, Morphologie). Im NEGRA-Format sind überkreuzende Kanten zulässig, d.h. aus der linearen Präzedenz zweier Knoten k1 < k2 kann nicht geschlossen werden, dass alle Kinder von k1 vor allen Kindern von k2 erscheinen. Zudem erscheinen Wortartenphrasen (d.i. Interpunktionen) nicht in der Satzstruktur, d.h. es gibt noch isolierte Knoten ("Wurzelstöcke"), die zusammen mit dem Syntaxbaum einen eigentlichen Wald bilden.
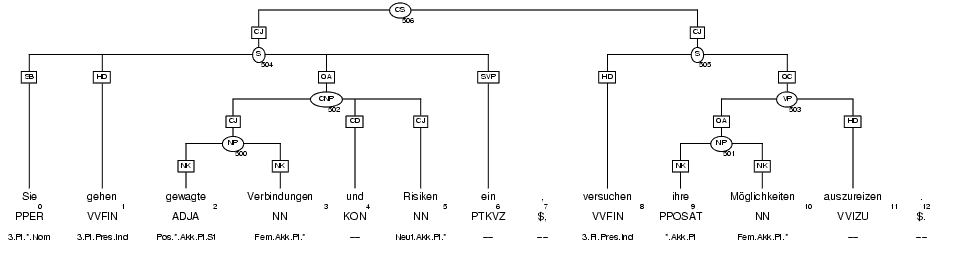
- Die grundlegende Repräsentation für die Struktur von Sätzen soll folgendermassen aussehen:
- Unmittelbare funktional determinierte Dominanzbeziehung (id/3)
- id(NodeID, Label, nodeID)
- Unmittelbare Präzedenzbeziehung (lp/2)
lp(nodeID, nodeID)
- Wortinformation (wd/3)
- wd(nodeID, Wortform, Morphologie)
-
-
- Für obigen Baum sähen die entsprechenden Klauseln auszugsweise so aus:
-
- id('CS'(506), 'CJ', 'S'(504)).
- id('S'(504), 'SB', 'PPER'(0)).
- id('S'(504), 'HD', 'VVFIN'(1)).
- ...
- id('$,'(7).
-
- lp('PPER'(0),'VVFIN'(1)).
- lp('VVFIN'(1),'CNP'(502)).
- lp('CNP'(502),'PTKVZ'(6)
-
- wd(0, 'Sie', [3,'Pl',_,'Nom']).
- wd(1, 'gehen', [3,'Pl','Pres','Ind']).
- wd(2, 'gewagte', ['Pos',_,'Akk','Pl','S1']).
- ...
- wd(7,',',_).
- ...
- ...
Ziel und Zweck
- Ziel dieser Arbeit ist es, ausgehend vom der oben angegebenen logischen Repräsentation eines Satzes, Extraktionsprädikate zu definieren, die das Anbindungsverhalten von Präpositionalphrasen zu untersuchen erlauben. Diese Extraktionsprädikate werden satzweise auf annotierte Korpora angewendet und sollen am Schluss 6-Tupel liefern, die folgende Information enthalten:
-
- tupel(Verb, EchterNominalKopf, AdjazenterNominalKopf, Präpositional, PPKern, Anbindungsentscheidung)
- Verb: v(Wortform, Verbzusatz, Reflexivität)
- Wortform: wörtliche Verbform
- Verbzusatz: wörtliches abtrennbares Verbpräfix
- Reflexivität: 0 oder 1
- EchterNominalKopf: n(Worform,Eigen) oder none
- wörtliche Wortform (Aber bei Bindestrichkomposita nur letztes Glied, bei Eigennamen eine Liste)
- Eigen: 0 oder 1
- AdjazenterNominalKopf: n(Wortform, Eigen) oder none
- wörtliche Wortform (Aber bei Bindestrichkomposita nur letztes Glied)
- Eigen: 0 oder 1
- Präpositional: p(Pre, Post) oder pronadv(Wortform)
- Pre: Wortform der Präposition
- Post: Wortform der Postposition oder none
- Wortform: Pronominal-Adverb
- PPKern: n(Wortform,Eigen), num(Wortform), a(Wortform), adv(Wortform), pron(Wortform), pronadv(Wortform) oder none
- wörtliche Wortform (Aber bei Bindestrichkomposita nur letztes Glied, bei Eigennamen eine Liste) Falls none, muss bei Präpositional ein Pronominaladverb eingetragen sein.
- Eigen: 0 oder 1
- Anbindungsentscheidung: n oder p
-
Arbeitsschritte
- Konversion vom prologifizierten NEGRA-Exportformat ins id/lp/wd-Format
- Definition von Hilfsprädikaten
- Systematische Zusammenstellung über mögliche Strukturen von Verbalkomplexen, Nominal- und Präpositionalphrasen im NEGRA-Format
- Definition von Prädikaten, die diese Strukturen in Sätzen matchen und die für die Informationsakkumulation relevante Information zurückgeben
- Definition der Konfigurationen, die potentielle 6-Tupel erzeugen
- Definition der Feinkriterien und Informationsakkumulationen für 6-Tupel
- Spezifische Kriterien, die bestimmte Kandidaten ausschliessen (elliptische Phrasen,…)
- Informationsakkumulation: Bestimmung von Reflexivität, Eigennamen, Adpositionsgliedern (Prä-, Post- und Circumfixen), Kompositionsauflösung, abgetrennte Verbpräfixe
- Programmierung der Extraktion als Generate-And-Test-Verfahren: Von Konfigurationen erzeugte Kandidaten werden getestet mit Feinkriterien und falls sie die Tests bestehen, mit Information akkumuliert und in der Wissensbasis abgelegt. Per Backtracking werden Alternativen erzeugt.
- Vergleiche der Resultate mit den Tupeln von M. Volk
Anforderung
- Interesse an eleganter deklarativer Programmierung mit Prolog (Das Programm muss nicht effizient sein, aber es soll möglichst elegant, durchsichtig und erweiterbar sein)
Benötigte Ressourcen
- annotierte Sätze im prologifizierten NEGRA-Exportformat
- Tupel von M.Volk
Literatur und Links
- Abschnitte aus M. Volks Habil
- Lezius, Wolfgang and König, Esther (2000) Towards a search engine for syntactically annotated corpora in Proceedings of the Fifth KONVENS Conference Ilmenau, Germany.
- NEGRA-Annotationsschema
Simon Clematide