[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ]
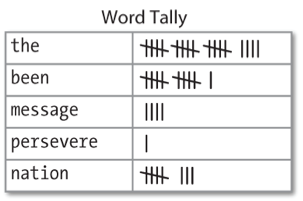
Häufigkeitsverteilungen: Vorkommen aufsummieren
Funktionen der Klasse nltk.FreqDist

Anwendung der Klasse nltk.FreqDist
Berechnen der häufigsten längsten Wörter → 23
Bivariate (bedingte) Häufigkeitsverteilungen
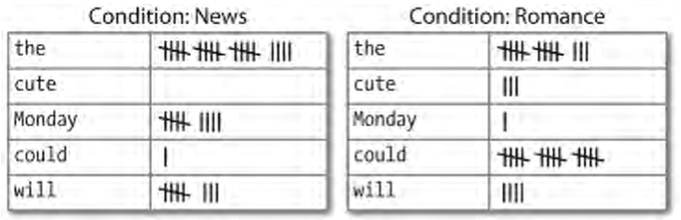
Bedingte Häufigkeiten berechnen
Modalverben in Abhängigkeit von Textkategorien → 24
Funktionen der Klasse nltk.ConditionalFreqDist

[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ]