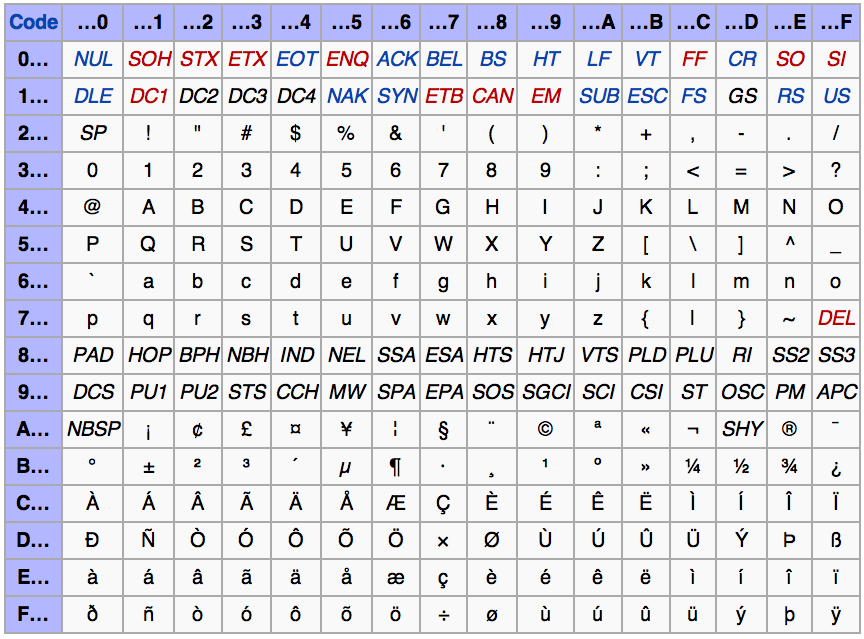
Quelle: Nach http://de.wikipedia.org/wiki/ISO_8859-1
| Abbildung 1.1.: | Zeichenkodetabelle von ISO-Latin-1 |
[ Weiter ] [ Seitenende ] [ Überkapitel ]
Zeichenkodierungen und Zeichensätze
Einschränkungen von ASCII
Die weitverbreiteste Zeichenkodierung mit 128 Kodes (7-Bit) unterstützt keine nicht-englischen Buchstaben.
Verschiedene Erweiterungen mit 8-Bit Kodierungen
Zeichenkodierungen mit 256 Kodes (1 Byte) für verschiedene Alphabete oder Betriebssysteme: ISO-8859-1, ISO-8859-9, Mac-Roman, Windows-1252
Universale Lösung Unicode
Unicode weist jedem Zeichen einen eindeutigen Zahlen-Kode und eine Kategorie zu. Unicode 6.0 definiert 109’449 graphische Zeichen
Kode-Tabellen von ASCII und ISO-8859-1 (auch latin1)
Quelle: Nach http://de.wikipedia.org/wiki/ISO_8859-1
| Abbildung 1.1.: | Zeichenkodetabelle von ISO-Latin-1 |
Kodierung und Dekodierung von Zeichen in Python
Zeichenkode berechnen aus Zeichen
Zeichen berechnen aus Zeichenkode
Datentyp str: Folgen von Zeichen als Bytes
Datentyp bestimmen und testen
Achtung: Beispiele immer selber testen!
Datentyp unicode: Folgen von Unicodes
Unicode Zeichenkodes
Datentyp bestimmen und testen
String-Literale notieren → 2
Speicher- und Transportformat UTF-8
Persistente Speicherung und Datenübertragung mit Unicode
UTF (Abk. für Unicode Transformation Format) beschreibt Methoden, einen Unicode-Wert auf eine Folge von Bytes abzubilden. Beispiele für UTF-8-Kodierungen

Quelle: http://de.wikipedia.org/wiki/UTF-8 Gründe für Format mit variabler Länge: Kompatibilität mit ASCII, kompakte Repräsentation, Sortierbarkeit, Erkennbarkeit von Zeichenanfängen
Textdatei als Bytefolgen
Die Repräsentation der Zeichen mit Kodes > 128 sind unterschiedlich.
Datei in UTF-8-Kodierung
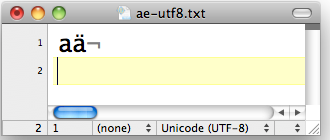
4 Bytes
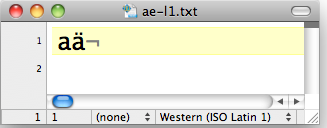
Datei in Latin-1-Kodierung
Kodierung der Python-Quellkodes deklarieren
Kodierungskommentar
Deklariere Kodierung immer mit Kodierungskommentar! Datei in UTF-8-Kodierung → 3 → 4
codecs: Kodieren und Dekodieren
Funktionen für Lesen und Schreiben von Unicode-Strings Einlesen von Latin-1 und schreiben von UTF-8 → 5
[ Weiter ] [ Seitenbeginn ] [ Überkapitel ]