10.3. Evaluation
Qualitätskriterien für Übersetzungen
Zielsprachliche Formulierungsgewandtheit (Fluency)
Wie fliessend (lexikalisch, syntaktisch und stilistisch korrekt und natürlich) erscheint der übersetzte
Text?
Quellsprachliche Ausdruckstreue (Faithfulness)
Wie genau wurde die ursprüngliche Formulierung übernommen?
Beispiel 10.3.1 (Klassiker: Fluent vs. Faithful).
- Japanisch: “fukaku hansei shite orimasu”
- Englisch I: “We are deeply reflecting (on our past behaviour, and what we did wrong, and
how to avoid the problem next time).”
- Englisch II: “We apologize.”
Qualitätskriterien für Übersetzungen
Adäquatheit einer Übersetzung
Wieviel der ursprünglichen Information wird in der Übersetzung wiedergegeben? Operationalisierbar
durch menschliche Urteile über einer nominalen Skala (Alles, Meiste, Viel, Wenig, Nichts).
Informativität einer Übersetzung
Reicht eine Übersetzung aus, um gewisse Fragen beantworten zu können. Operationalisiserbar durch
task-basierte Evaluation via Multiple-Choice-Aufgaben zum Inhalt.
Posteditierungsaufwand
Wieviel Zeit benötigt die Postedition? Wieviele Sätze oder Texte brauchen wieviele Modifikationen?
Bei METEO-System brauchten 1991 ca. 4% der Texte eine Postedition (bzw. HT).
Automatische Evaluation
Idee
Automatische Evaluation misst die Qualität einer maschinellen Übersetzung, indem sie mit einer oder
besser mehreren menschlichen Referenz-Übersetzungen
verglichen wird.
Vorteile
Menschliche Evaluation ist aufwändig
und langsam
, automatische Berechnung einer metrischen Güte ist billig und schnell.
Definition 10.3.2 (Bilingual Evaluation Understudy (BLEU)). Eine der aktuell wichtigsten Metriken
zur automatischen bilingualen Evaluation ist der BLEU-Score
.
10.3.1. BLEU
BLEU: Unigramm-Präzision
- MT: It is a guide to action which ensures that the military always obeys the commands of
the party.
- MT: It is to insure the troops forever hearing the activity guidebook that party direct.
- HT: It is a guide to action that ensures that the military will forever heed Party commands.
- HT: It is the guiding principle which guarantees the military forces always being under
the command of the Party.
- HT: It is the practical guide for the army always to heed the directions of the party.
Definition 10.3.3 (Unigramm-Präzision P1). Die Unigramm-Präzision
(Token-Präzision) eines Übersetzungskandidaten misst, wie hoch der Anteil der Wörter aus allen
Referenzübersetzungen an allen Tokenvorkommen eines Kandidaten ist: 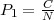
N = Anzahl Token des Kandidaten; C = Anzahl Token des Kandidaten, welche in einer
Referenzübersetzung erscheinen
Unigramm-Evaluation
Frage
Wie hoch sind P1 von MT1 und MT2?
Tokenvorkommen
- MT1: . a action always commands ensures guide is it military of party that the the the to
which
- MT2: . is it party that the the to
Notwendigkeit für Clipping
Problem der Wiederholung
- Kandidat: the the the the the the the
- HT1: the cat sat on the mat
- HT2: there is a cat on the mat
Wie hoch ist die P1 des “idiotischen” Kandidaten? 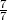
Clipping der Kandidatenvorkommen
Ein Token darf maximal
sooft gezählt werden, wie es in einer einzelnen Referenzübersetzung vorkommt.
Wie hoch ist P1 des Kandidaten mit Clipping? 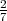
Uni-, Bi-, Tri- und Quadrigramme
Längere Textabschnitte im Vergleich
Welche N-Gramme aus den Referenztexten finden sich im MT-Kandidaten?
- MT: It is a guide to action which ensures that the military always obeys the commands of
the party.
- HT: It is a guide to action that ensures that the military will forever heed Party commands.
- HT: It is the guiding principle which guarantees the military forces always being under
the command of the Party.
- HT: It is the practical guide for the army always to heed the directions of the party.
Geometrisches Mittel der N-Gramm-Präzisionen
Die Precisionwerte der 1-4-Gramme eines Kandidaten werden geometrisch gemittelt
: 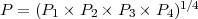
Problem der Kürze
- Kandidat: of the
- HT1: It is the guiding principle which guarantees the military forces always being under
the command of the Party.
Wie hoch ist die P1 des Kandidaten? 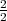
Recall-Mass kompensieren
Normalerweise würde ein Präzisionsmass mit Recall verrechnet, um solche Effekte zu mindern. Wir
haben aber mehrere Referenzübersetzungen. Als Ausweg wird ungewöhnliche Kürze des Kandidaten
bestraft.
Strafabzug für Kürze über Korpus
- Schritt: Bestimme die Gesamt-Länge c der Kandidatenübersetzung.
- Schritt: Bestimme die Gesamt-Länge r der Referenzübersetzungen, indem jeweils die
kürzeste (NIST-Variante) oder zur höchsten Bewertung führende Referenzübersetzung
genommen wird.
- Schritt: Bestimme Kürze: brevity = r∕c
- Schritt: Bestimme Strafabzug (brevity penalty):
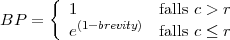
Beispiel 10.3.4 (Realistischer Faktor).
Wenn Kandidatenübersetzung 1000 Token zählt (c = 1000) und Referenzlänge als 1100 Token zählt
(l = 1100), dann BP = e1−1.1 = e−0.1 = 0.905
BLEU als Formel
BLEU-Score ergibt sich aus Multiplikation von Brevity Penalty mit der geometrisch gemittelten
Präzision aus 1-4-Grammen.
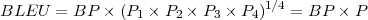 Wert
von 1 heisst “perfekte” Übereinstimmung, Wert 0 heisst keine Übereinstimmung.
Wert
von 1 heisst “perfekte” Übereinstimmung, Wert 0 heisst keine Übereinstimmung.
Eigenschaften
BLEU betont enge lokale Übereinstimmung
und vernachlässigt Unstimmigkeiten, welche sich darüber hinaus ergeben können:“Ensures that the
military it is a guide to action which always obeys the commands of the party.” wäre gleich gut wie
Kandidat 1.
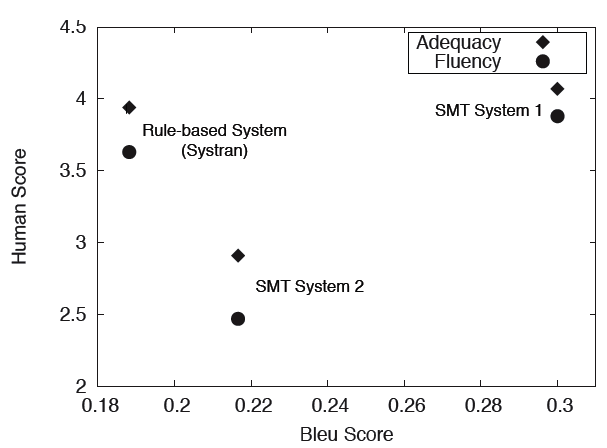
Wie zuverlässig bildet BLEU das menschliches Urteil ab?
- Wortvarianz
(Synonyme) wird nur berücksichtigt, wenn in Referenzübersetzungen enthalten
- Unwichtige und wichtige Inhalts-Wörter
werden gleich behandelt
- Für denselben BLEU-Score
gibt es Millionen von Kombinationen mit unterschiedlichster Übersetzungsqualität
- Regelbasierte Übersetzungssysteme werden gegenüber statistischen gerne abgestraft
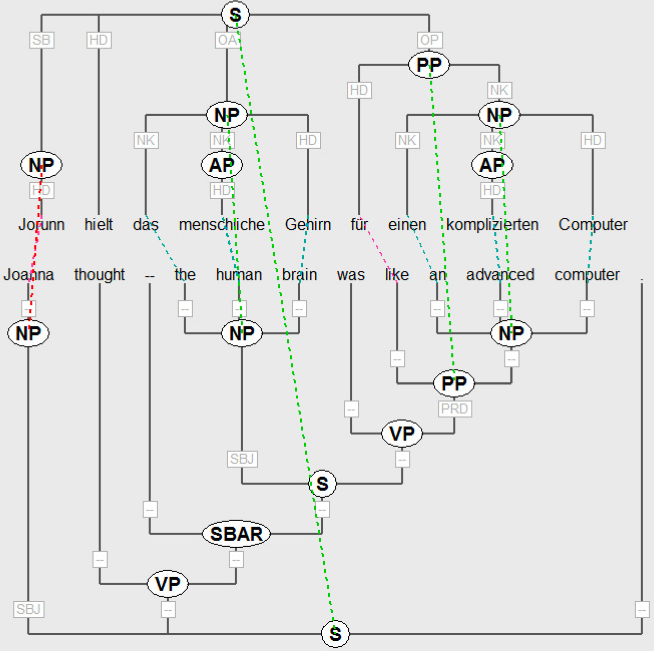
10.3.2. Parallele Baumbanken
Einsatz von parallelen Baumbanken
- Korpus von bilingual syntaktisch annotierten Sätzen
- Annotation von (Miss-)Matches der Übersetzungen durch Zuordnung auf Wort- und
Konstituentenebene
Anwendungen
- Übersetzungsevaluation mit vertieftem linguistischen Wissen
- Evaluationskorpus für Wort-, Phrasen- und Satzalignierung
- Trainingskorpus für Regeln der die Transferübersetzung