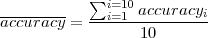Definition 6.2.5 (Genauigkeit, engl. accuracy). Die Tagging-Genauigkeit
über einem Text mit N Token ist der Anteil der korrekt getaggten Token.
Formal: Sei E die Anzahl von falsch getaggten (Vorkommen von) Token:
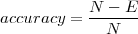
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Definition 6.2.1. Die Evaluation eines Resultats oder eines Verfahrens ist die Zuordnung eines Wertes auf einer Werteskala aufgrund einer Messmethode.
Definition 6.2.2 (Qualität einer Evaluation). Die Qualität einer Messmethode basiert auf ihrer Validität und Reliabilität.
Definition 6.2.3 (Validität, Gültigkeit, Angemessenheit). Die Validität einer Messmethode sagt aus, ob das, was gemessen werden soll (Messintention) auch das ist, was effektiv gemessen wird.
Definition 6.2.4 (Reliabilität, Zuverlässigkeit, Genauigkeit). Die Reliabilität einer Messmethode sagt aus, wie genau und reproduzierbar die Messresultate sind.
Überlegungen zu Reliabilität und Validität
Messintention
Es soll das Verständnis von Studierenden über das Thema reguläre Ausdrücke mittels eines Multiple-Choice-Tests geprüft werden.
Überlegung I
Wie müssen die Fragen des Multiple-Choice-Tests beschaffen sein, damit die Reliabilität und Validität hoch ist?
Überlegung II
Was passiert bezüglich der Qualität der Evaluation, wenn derselbe Test von der gleichen Person mehrmals gemacht wird?
Systemverbesserung
Von System A wird eine neue Version A’ erstellt, wobei eine Komponente Z modifiziert worden ist. Die Evaluation von System A und A’ hilft einzuschätzen, inwiefern die Komponente Z das System optimiert.
Systemvergleich
Um ein Problem P zu lösen, steht ein System A und ein System B zur Verfügung. Die Evaluation anhand einer Testaufgabe T zeigt auf, welches System besser ist.
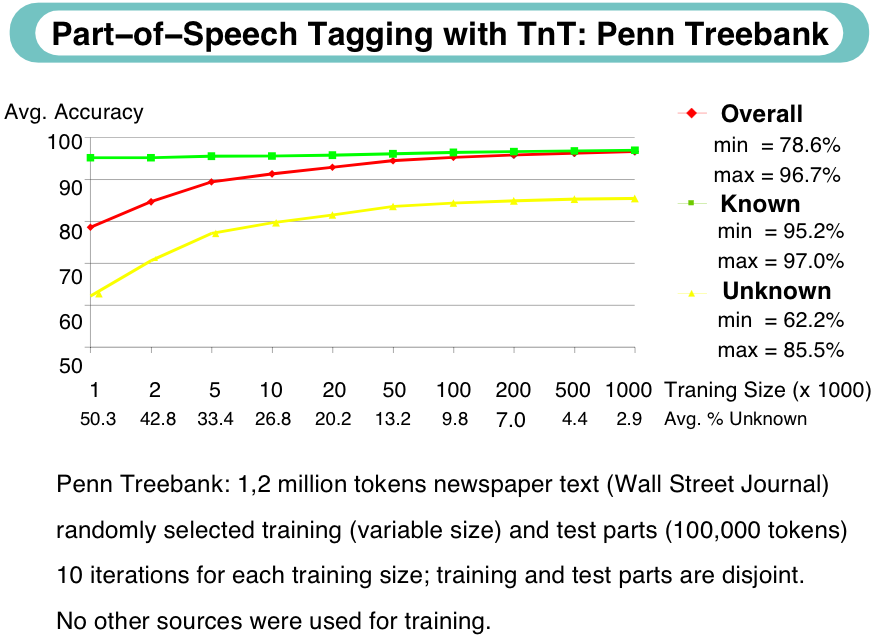
POS-Tagger-Evaluation: Genauigkeit
Definition 6.2.5 (Genauigkeit, engl. accuracy). Die Tagging-Genauigkeit
über einem Text mit N Token ist der Anteil der korrekt getaggten Token.
Formal: Sei E die Anzahl von falsch getaggten (Vorkommen von) Token:
Beispiel 6.2.6 (Genauigkeitsberechnung).
Die Korrektheit des TnT-Taggers bei einem Training über 1 Million Token der Penn Treebank beträgt
96.7%. Wieviele Token wurden im Testkorpus von 100’000 Token falsch getaggt?
Wenn man nur über 1’000 Token trainiert, sind im Schnitt etwa 31’400 Fehler im Testkorpus von 100’000 Token. Wie hoch ist die Genauigkeit?
Beispiel 6.2.7 (Verbesserung von Tagging-Resultaten).
Hans ist nicht zufrieden mit den 96.7% Genauigkeit des TnT-Taggers über der Penn Treebank. Er
schreibt ein Pattern-Matching-Programm, das nach dem Tagging angewendet wird und das möglichst
viele Fehler des Taggers noch korrigiert. Nach 2 Jahren hat er damit für die Penn Treebank eine
Genauigkeit von 99.8% erreicht.
Was ist von der Aussage von Paul zu halten, dass er einen POS-Tagger für Englisch gemacht hat, der eine evaluierte Genauigkeit von 99.8% hat?
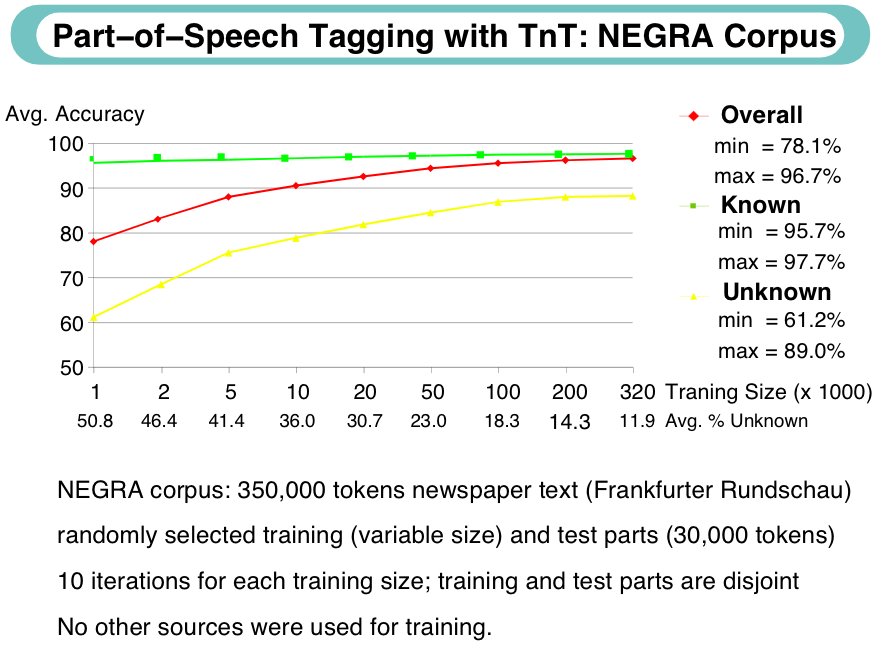
Häufigste Tagging-Fehler von TnT im NEGRA-Korpus
Legende zur Tabelle ???
Tagt: Korrektes Label; Tagf: Falsch getaggtes Label
Freqt: Vorkommenshäufigkeit des korrekten Labels; Freqf: Vorkommenshäufigkeit des falschen
Labels
Erel.: Relative Fehlerquote, d.h. Anteil dieses Fehlers am Gesamtfehler
Ant.: Anteil der falschen Tags an den korrekt erkannten
|
Genauigkeit unter 10-facher Kreuzvalidierung
Definition 6.2.8 (10-fache Kreuzvalidierung, engl. ten-fold cross-validation). Bei der 10-fache Kreuzvalidierung werden die vorhandenen Daten in 10 Teile aufgeteilt. In 10 Testläufen wird jeweils 1/10 der Daten als Testmaterial verwendet und die restlichen 9/10 der Daten als Trainingsmaterial.
Generalisierung von 10 auf k
Die Verwendung von 10 hat sich als gute und bewährte Praxis erwiesen. Im Prinzip kann man aber 10 durch irgendeine Zahl k ≥ 1 ersetzen.
Recall (Ausbeute, Abdeckung, Vollständigkeit)
Definition 6.2.10. Recall
ist ein Evaluationsmass, das den Anteil der korrekten Antworten (Entscheidungen) eines Systems
gemessen an allen möglichen korrekten Antworten angibt.
Formal: Sei Nt die Anzahl aller möglichen korrekten Antworten und At die Anzahl der korrekten
Antworten des Systems.
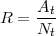
Beispiel 6.2.11 (Recall eines Taggers).
Ein Tagger hat von 800 vorhandenen VVFIN in einem Testkorpus 600 korrekt als VVFIN klassifiziert.
At = 600 und Nt = 800. Der Recall berechnet sich als: R = 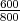 = 75%
= 75%
Precision (Genauigkeit, Präzision)
Definition 6.2.12. Precision
ist ein Evaluationsmass, das den Anteil der korrekten Antworten (Entscheidungen) eines Systems
gemessen an allen gegebenen Antworten des Systems angibt.
Formal: Sei A die Anzahl aller Antworten und At die Anzahl der korrekten Antworten des
Systems.
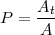
Beispiel 6.2.13 (Precision eines Taggers).
Ein Tagger hat in einem Testkorpus 1’000 Token als VVFIN klassifiziert, aber nur 600 davon waren
tatsächlich VVFIN.
At = 600 und A = 1000. Die Precision berechnet sich als: P = 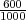 = 60%
= 60%
Definition 6.2.14 (F1-Measure). Das F-Measure
ist ein Evaluationsmass, das Precision und Recall eines Systems gleichgewichtet (zum harmonischen
Mittelwert) verrechnet.
Formal: Sei P die Precision und R der Recall eines Systems:
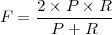
Beispiel 6.2.15 (F-Mass eines Taggers).
Ein Tagger hat in einem Testkorpus eine Präzision von 60% und ein Recall von 75% für VVFIN.
Das F-Measure berechnet sich somit: F = 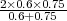 = 66.6%
= 66.6%
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]