8.3
twolc: Ein Formalismus für Alternationen
8.3.1
Formalismus
Ein Formalismus für phonologische Alternationen
twolc-Sprache
Die twolc-Sprache ist eine auf lexikographische Bedürfnisse zugeschnittene Regel-Notation, um die
Bedingungen (ortho-)graphischer und phonologischer Alternationen zu beschreiben.
- Die Zwei-Ebenen-Regeln spezifizieren Beschränkungen
(constraints) über das Vorkommen von Symbolpaaren
.
- Der twolc-Kompiler kann die Regeln automatisch in ET übersetzen.
- Die Regeln müssen immer gleichzeitig parallel
jedes Symbolpaar eines Zeichenkettenpaars erlauben – 𝜖 wird dabei wie ein normales Symbol der
Länge 1 betrachtet.
- Wegen der Einschränkung auf Vorkommen von 𝜖 in Symbolpaaren lassen sich die
Transduktoren der verschiedenen Regeln als Spezialfall zu einem grossen Transduktor
schneiden.
Phänomene mit 2-Ebenen-Regeln in GERTWOL
- Umlautung
bei Substantiven
- Die e-Erweiterung
im IND PRÄS SG2/3 und PL2, IMP PRÄS PL2, IND PRÄT und PART PERF bei schwachen
Verben, deren Stamm entweder auf -d oder -t endet oder auf -m oder -n ausgeht, vor dem ein
anderer Konsonent (kein -l oder -r) steht: reden → redete (nicht: redte); atmen → atmete (nicht:
atmte)
- Der n-Schwund
im PL DAT bei auf -n ausgehenden Substantiven: Laden → Läden (nicht: Lädenn)
- Die (alte) Rechtschreibung
des ss/ß: Kuß → Küsse; vermissen → vermißt
- Die alte Rechtschreibung
an der Nahtstelle in Komposita (drei Konsonanten): Schnitt + Tulpe → Schnittulpe
Aufbau einer twolc-Datei
Alphabet (feasible pairs)
Nach dem Schlüsselwort Alphabet werden alle möglichen Symbolpaare des Regeltransduktors
aufgelistet.
Regeln
Nach dem Schlüsselwort Rules folgen die Regeln, denen jeweils ein treffender Name in
Anführungszeichen vorangeht.
Reguläre Konstrukte
In den Regeln sind die meisten regulären Operatoren für reguläre Sprachen (nicht Relationen!)
zugelassen. Sie dürfen aber nie
nur auf eine Seite eines Symbolpaars angewendet werden: Verboten: a:[b+].
Im Gegensatz zu den Ersetzungsregeln von xfst dürfen alle Bestandteile sich auf die obere und die
untere Sprache beziehen (deshalb: Zwei-Ebenen-Regeln).
Semantik der Regel-Operatoren
Ausschnitt aus GERTWOL ▸▸▸
Alphabet a b c d e f g h i j k l m n o p
q r s t u v w x y z ä ü @U:0 #:0 %_:0 ;
Rules
"Uml a~ä"
a:ä <=> _ [ \ [#: | a: | o: | u: ]]* @U: ;
_ u: [ \ [#: | a: | o: | u: ]]* @U: ;
"Uml u~ü"
u:ü <=> \a: _ [#: | a: | o: | u: ]* @U: ;
Notationen der Form "c:" (oder ":c") bezeichnen nicht die Identitätsrelation, sondern alle möglichen
Symbolpaare aus dem Alphabet (feasible pairs), welche auf der einen Seite das Symbol c aufweisen.
8.3.2
Benutzerschnittstelle
Kompilieren von twolc-Dateien
Einlesen und kompilieren
$ twolc
twolc> read-grammar rules.twol
reading from "rules.twol"...
Alphabet... Rules...
"Uml a~ä" "Uml u~ü"
twolc> compile
Compiling "rules.twol"
Expanding... Analyzing...
Compiling rule components:
"Uml a~ä" "Uml u~ü"
Compiling rules:
"Uml a~ä"
a:ä <=> 2 1
"Uml u~ü"
u:ü <=>
Done.
Inspizieren und exportieren
twolc> show-rules
"Uml a~ä"
? a o u a:ä @U:0
1: 1 2 1 1 3 1
2: 5 2 1 5 3
3. 4 4 1
4. 4 1
5: 5 2 1 1 3
Equivalence classes:
((? b c d e f g h i j k l m n p
q r s t v w x y z ä ü _:0) (a)
(o #) (u u:ü) (a:ä) (@U:0))
...
twolc> save-binary rules.fst
Writing "rules.fst"
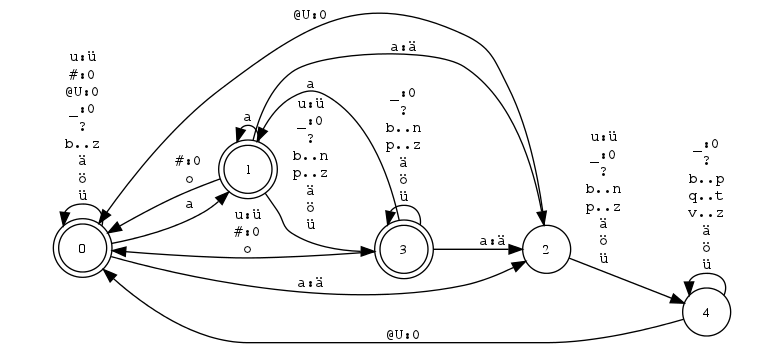
Zustandsdiagramm für Regel “Uml a˜ä”
"Uml a~ä"
a:ä <=> _ [ \ [#: | a: | o: | u: ]]* @U: ;
_ u: [ \ [#: | a: | o: | u: ]]* @U: ;
Zusammenfügen von Lexikon und Regeln
Einlesen
$ lexc
lexc> compile-source lexicon.lexc
...
lexc> random-surf
NOTE: Using SOURCE.
*mau_se@U
*mau_se@U
...
lexc> random-lex
NOTE: Using SOURCE.
*mau_s+S+FEM+SG+NOM
*mau_s+S+FEM+SG+NOM
...
lexc> read-rules rules.fst
Opening ’rules.fst’...
2 nets read.
Verknüpfen und exportieren
lexc> compose-result
No epenthesis.
Initial and final word boundaries
added. ..Done.
1.9 Kb. 27 states, 35 arcs, 8 paths.
Minimizing...Done.
1.7 Kb. 20 states, 26 arcs, 8 paths.
lexc> random-surf
Use (s)ource or (r)esult? [r]: r
NOTE: Using RESULT.
*maus
*mäusen
...
lexc> save-result lextrans.fst
Opening ’lextrans.fst’...
Done.