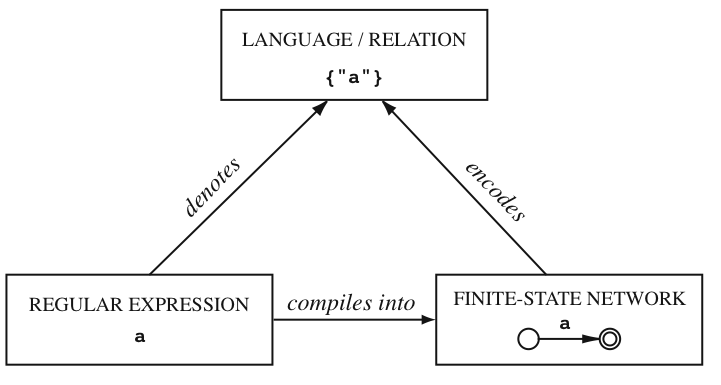
| Abbildung 4.3: | Beziehung zwischen formalen Sprachen, regulären Ausdrücken und endlichen Automaten (aus [BEESLEY und KARTTUNEN 2003b]) |
[ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Reguläre Ausdrücke (RA) in XFST
Beispiel 4.2.1 (Einlesen und Kompilieren eines RA mit xfst).
read regex RA ; # EA auf
Stack
define varname RA ; # EA als
Variable
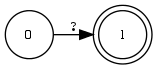
Beziehung zwischen RA, DEA und formalen Sprachen
Zu jedem regulären Ausdruck RA existiert mindestens ein EA, der die vom RA bezeichnete reguläre
Sprache akzeptiert.
| Abbildung 4.3: | Beziehung zwischen formalen Sprachen, regulären Ausdrücken und endlichen Automaten (aus [BEESLEY und KARTTUNEN 2003b]) |
Zulässige Einzelsymbole
Jedes der folgenden alphanumerischen Symbole x bezeichnet als regulärer Ausdruck (RA) die Sprache {x}:
%-geschütztes Zeichensymbol (escape symbol)
Spezialsymbole
Das Zeichen % gefolgt von einem der folgenden Symbole x
0 ? + * | . , : ; - / % ~ ( ) [ ] { } " \
bezeichnet als RA die Sprache {x}.
Hinweise
Mehrzeichensymbol
Jedes Zeichen x zwischen doppelten Hochkommata ausser
\, " und getippter Zeilenwechsel
bezeichnet als RA die Sprache {x}.
Hinweis
Zwischen Hochkommata verlieren alle Zeichen ihre Sonderbedeutung.
Backslash-Notation zwischen doppelten Hochkommata
Backslash-Notation für nicht-druckbare Zeichen
und numerische Zeichenkodes
sind zwischen doppelten Hochkommata möglich.
Hinweise
Symbole aus mehreren Zeichen (multicharacter symbols)
Mehrzeichensymbol
Jede Folge von normalen Zeichen oder %-geschützten Zeichen ist ein Mehrzeichensymbol x, das als RA die Sprache {x} bezeichnet.
Hinweis
Mehrzeichensymbole werden von einem endlichen Automaten in einem einzigen Zustandübergang konsumiert.
Zitierte Mehrzeichensymbole
Auch Mehrzeichensymbole lassen sich mit doppelten Hochkommata zitieren. Es gelten die gleichen
Regeln wie bei den Einzelzeichensymbole. In zitierten Symbolen verliert % seine Rolle als
Escape-Zeichen.
Guter Programmierstil
Epsilon-Symbol
Das Ziffern-Zeichen 0 ist ein Spezial-Symbol, das als RA die Sprache {𝜖} bezeichnet.
Hinweise
Um die Ziffer 0 als Einzelzeichen zu erhalten, muss sie geschützt oder zitiert werden.
Die Sprache {𝜖} kann auch mit "" oder [] notiert werden.
Any-Symbol
Das Zeichen ? ist ein Spezial-Symbol, das als RA die Sprache aller Zeichenketten aus 1 Symbol
bezeichnet.
Hinweise
Reguläre Operatorenausdrücke in xfst
Wenn die beiden RA A und B die Sprachen A bzw. B bezeichnen, dann bezeichnet der
RA
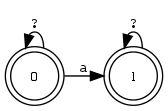
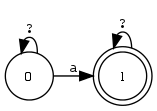
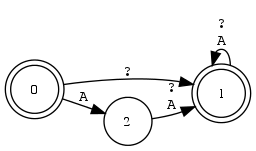
Beispiel 4.2.9 (Präzedenz von Operatoren). Welcher der beiden RA entspricht dem Zustandsdiagramm?
Hinweise
Klammernotation für Konkatenation
Jeder RA wie {TEXT} steht für die Konkatenation aller Einzelzeichen, die zwischen den geschweiften
Klammern notiert sind: [T E X T].
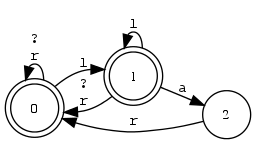
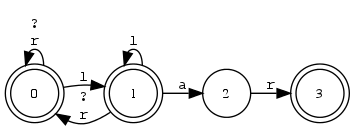
Beispiel 4.2.10 (xfst und Zustandsdiagramm).
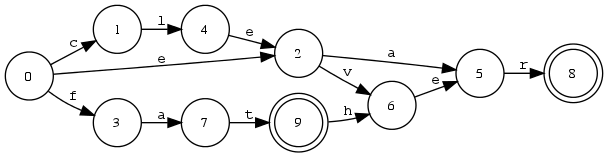
Hinweis
Endliche Automaten speichern Lexika kompakter als Suchbäume (Buchstabenbäume, Trie). Grund: Nicht bloss gemeinsame gemeinsamen Präfixe, sondern auch gemeinsame Suffixe sind nur einmal repräsentiert.
Operatoren für Komplemente
Wenn der RA A die Sprache A über Σ bezeichnet, dann bezeichnet der RA
Universale Sprache, Komplement und Subtraktion
Für das Sprach-Komplement von A gilt die folgende Äquivalenz
[ ˜ A ] = [?* - A ]
Was gilt für das Komplement des Alphabets?
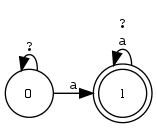
? als RA-Symbol vs. ? als Kantenbeschriftung in EA
Das ANY-Symbol ? steht als RA für die Sprache aller Zeichenketten der Länge 1.
Beispiel 4.2.11 (Interpretation von ˜ A).
Im regulären Ausdruck ?*, der die universale Sprache bezeichnet, bedeutet das Fragezeichen nicht dasselbe wie als Kantenbeschriftung. Die Verwendung des gleichen Zeichens für unterschiedliche Zwecke mag verwirren. Die Funktion als Kantenbeschriftung und als regulärer Ausdruck lässt sich aber immer leicht unterscheiden.
Definition 4.2.12 (UNKNOWN-Symbol). Das UNKNOWN-Symbol ? steht als Kantenbeschriftung für diejenigen Symbole des Eingabealphabets, welche nicht explizit im Sigma aufgeführt sind (dem Sigma unbekannt). Bei foma wird für das UNKNOWN-Symbol @ verwendet.
Wozu kann es nützlich sein, das Alphabet nicht vollständig aufzählen zu müssen?
Operatoren für Enthalten-Sein
Wenn der RA A die Sprache A über Σ bezeichnet, dann bezeichnet der RA
Operator für Beschränkung via Kontext
Der RA [ A => L _ R ] (expression restriction) restringiert alle Vorkommen von Teilzeichenketten
a aus A. Jedem a muss eine Zeichenkette aus L vorangehen und eine Zeichenkette aus R
nachfolgen.
Beispiel 4.2.14 (Ausdrucksrestriktion). Die Sprache von [ a => b _ c ] umfasst das Wort back-to-back oder bc, aber nicht das Wort cab oder pack.
Schrittweise Definition von [ A => L _ R ]
define Maolv [~[?* L]] A ?* ; # Mindestens ein A ohne L vorher
define Maorn ?* A [~[R ?*]] ; # Mindestens ein A ohne R nachher
define WederMaolvNochMaorn ~Maolv & ~Maorn ;
Hinweis
Die Sprache des Restriktions-Ausdrucks schränkt nur diejenigen Zeichenketten ein, welche als Teilzeichenkette ein Wort a aus A enthalten.
Wortende verankern in der Kontext-Beschränkung
Die Spezialmarkierung für Wortende
Die Kontexte in [ A => L _ R ] sind gegen Aussen implizit mit der universalen Sprache konkateniert: [ A => ?* L _ R ?*]. Die Spezialmarkierung .#. bedeutet in den Kontexten Verankerung am Wortende und verhindert so die implizite Verkettung. Im EA ist .#. nicht vorhanden, es kann aber wie ein Symbol in die RA eingefügt werden.
Operator für Beschränkung des Kontexts
Der RA [ A <= L _ R ] (context restriction) erlaubt Kontexte aus L gefolgt von R nur, wenn
dazwischen eine Teilzeichenketten a aus A vorkommt.
Beispiel 4.2.16 (Kontextrestriktion). Die Sprache von [ a <= b _ c ] umfasst das Wort back-to-back oder cb, aber nicht das Wort bc oder bxc.
Hinweis zu Restriktion
Der Operator [ A <=> L _ R ] vereinigt die Beschränkungen. A ist ausserhalb von L und R verboten (expression restriction) und der Kontext L _ R ist verboten, ausser ein String aus A steht dazwischen (context restriction).