|
|
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenende ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]
Ebenen der Analyse sprachlicher Information
F: Womit befasst sich die Morphologie? A: Wortstruktur und Wortbildung
Beispiele morphologischer Analyse
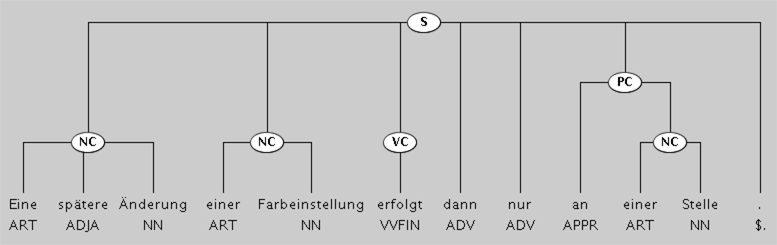
Hierarchische Wortbildungsanalyse von canoo.net
|
|
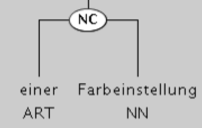
Flache Wortstrukturanalyse von GERTWOL
Nützlichkeit morphologischer Analyse
Bestimmung der Grundform flektierter Wörter
Linguistisch fundierte Normalisierung: Mütter → Mutter Im Gegensatz zum blossen Abschneiden (Trunkierung) oder heuristischen Reduzieren (Stemming)
Auflösung von Wortableitungen
Assoziieren von strukturell verwandten Begriffen: baulich → Bau Linguistik → linguistisch Interessant sind Ableitungen, welche nur Wortartwechsel beinhalten!
Zerlegung/Ergänzung von Komposita
Insbesondere Neu- bzw. Spontanbildungen, deren Bedeutung sich aus den Einzelteilen ergibt: Wohnbauförderungsmöglichkeiten → Wohnbauförderung Text- und Diskurstheorie → Texttheorie Interessant sind Teile, welche im Gebiet belegt sind!
Probleme morphologischer Analysen: Mehrdeutigkeit
Kategorielle Mehrdeutigkeit
Exakte morphologische Analyse in einem Text setzt die Bestimmung der Wortart voraus!
Strukturelle Mehrdeutigkeit
Unterschiedliche Analysen bzw. unklare Gruppierung der Bestandteile
Probleme morphologischer Analyse
Unvollständigkeit
Überanalyse
Kein Unterschied zwischen lexikalisierter Form und produktiver Bildung!
Endliche Automatentechnik zur Analyse
Hocheffiziente Speicherung und Verarbeitung!
|
|
Definition 1.3.1 (nach [BUSSMANN 1990]). Wort . Intuitiv vorgegebener und umgangssprachlich verwendeter Begriff für sprachliche Grundeinheiten, dessen zahlreiche sprachwissenschaftliche Definitionsversuche uneinheitlich und kontrovers sind.
Beispiel 1.3.2 (Was ist ein Wort?).
Tokenisierung: Vom Zeichenstrom zur Folge von Tokens
Rohdaten
Rohe, elektronische Sprachdaten liegen in Dateien vor, welche nur eine Folge von Einzelzeichen, d.h. ein kontinuierlicher Zeichenstrom sind.
Token: Einheit der Textsegmentierung
Tokens sind die grundlegenden Analyseeinheiten nachgeschalteter sprachtechnologischer Systeme wie Wortartenbestimmung, Wortkorrektur, morphologische Analyse, Lexikonzugriff, syntaktische Analyse.
Tokenisierung: Im Prinzip einfach, aber trotzdem schwierig
Satz-Segmentierung
Wer jeden Punkt als Satzende interpretiert, liegt im Englischen in 8-45% der Fälle daneben.
Beispiel 1.3.3 (Verschmelzung im Englischen).
It was due Friday by 5 p.m. Saturday would be too late.
Wort-Segmentierung in nicht-segmentierten Schreibsystemen
Die Tokenisierung von chinesischen Texten ist anspruchsvoll, da keine Wortabstände gemacht werden.
|
Oben Chinesisch – unten englische Version
|
Token-Normalisierung
Die Modifikation der Zeichen des Eingabestromes kann von einfachsten orthographischen Varianten
, Rückgängigmachen von Silbentrennung, Rechtschreibekorrektur bis linguistisch motivierten
Operationen gehen.
Beispiel 1.3.4 (Normalisierungen).
Definition 1.3.5 (Wortarten-Tagger ). Ein Wortarten-Tagger (engl. Part-of-Speech Tagger, kurz POS-Tagger) ist ein Programm, das für jedes Token eines Textes die korrekte Wortart bestimmt, indem es ein Klassifikationskürzel (z.B. Penn-Tagset) als Tag zuordnet.
Mehrdeutigkeit
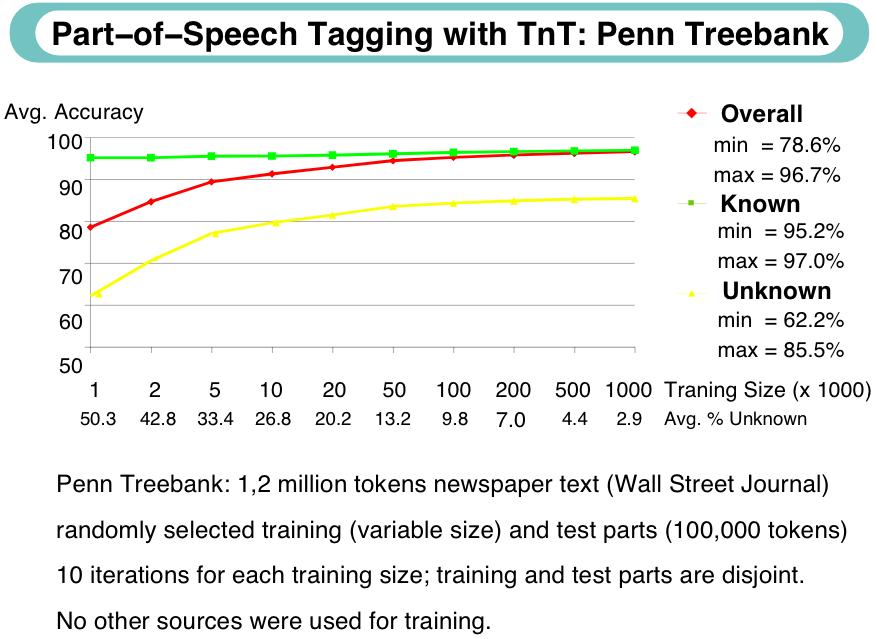
Im Brown-Corpus (1 Mio. Token) haben 11% aller Wortformen mehr als 1 mögliches Tag. Das entspricht jedoch 40% der Token. Warum?
Beispiel 1.3.6 (Typische Tag-Ambiguität im Englischen).
| Nomen | |||||
| Adverb | |||||
| Verb (Partizip) | Adjektiv | Verb | |||
| Pronomen | Verb (Past) | Präposition | Verb | Artikel | Nomen |
| She | promised | to | back | the | bill |
Nutzen und Anwendung des POS-Tagging
POS-Tagging hat sich als eine eigenständige sprachtechnologische Anwendung
erwiesen, welche effizient und zuverlässig durchgeführt werden kann, und für verschiedenste Zwecke
nützlich ist: Lemmatisierung, Lexikographie, Terminologierkennung, Spracherkennung, Vorstufe der
syntaktischen Analyse usw.
Beispiel 1.3.7 (Sprachsynthese/Bedeutungsdisambiguierung).
Beispiel 1.3.8 (Bestimmen der Grundform (Lemmatisierung)).
Der Apostroph in der phonetischen Umschreibung steht vor der hauptbetonten Silbe.
Lexikalische Baseline
Nimm für jedes Token das Tag, mit dem es am häufigsten vorkommt. Ergibt bis 90% richtige Entscheidungen.
Beispiel 1.3.9 (Tag-Verteilung in Zeitungstext (80’000 Tokens)).
Optimierungspotential: Berücksichtigung des Kontexts
Berücksichtige den linken Kontext (Tags und Tokens) und ev. den rechten Kontext (Tokens), um die Baseline-Entscheidung umzustossen.
Evaluation von lernenden Verfahren
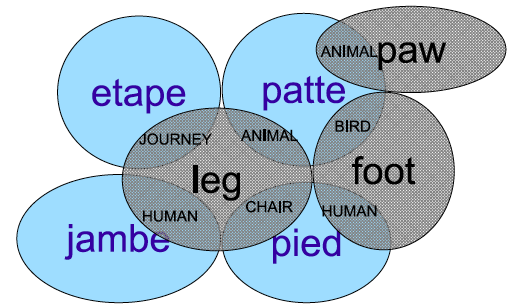
Wie lässt sich die Bedeutung eines Worts angeben?
Klassische Charakterisierung: Umschreibung, Definition
Relationale lexikalische Semantik = Bedeutungsbeziehungen
Durch Angabe von Synonymen, Hypernymen, Hyponymen, Antonymen usw., welche ein Netz von verknüpften Bedeutungen ergeben (wie Thesaurus)
Beispiel 1.3.11 (Wortnetze für viele Einzelsprachen (engl. "WordNet", dt. "GermaNet")).
Bedeutungsdesambiguierung im Kontext
Word-Sense-Desambiguation und Maschinelle Übersetzung
Lexikalisierung und Bedeutung über Sprachgrenzen hinweg
Spezialsprachliche Fachbegriffe
Weisen als Zusammensetzung oder Mehrwortterme oft komplexe Struktur auf:
Computer, elektronischer Rechenanlage, free indexing, unendliche Reihe
Aufgaben
Identifiziere spezifisch fachsprachliche Wortbestandteile!
Diskussion
Identifiziere Termkandidaten anhand der Wortarten!
Sprachspezifische Wortgruppenmuster für Nominalphrasen
Eigennamen – “Named Entities”
Uninteressant für Linguistik – aber vital für praktische Systeme
Beispiel 1.3.12 (Katalogdaten mit Eigennamen).
Lise Meitner an Otto Hahn: Briefe aus den Jahren 1912 bis 1924
Erkennung von Personennamen
Meistens Verwendung von Listen und Mustern mit Kontexteinschränkungen:
Vorname gefolgt von grossgeschriebenem Wort
Einfache semantische Desambiguierung
“Hahn” hat hier nichts mit Geflügel oder Sanitärinstallation zu tun! Eigennamen kollidieren mit normalen Wörtern!
Weitere “Named Entities”: Interessierende Grössen
Entitäts-bezogenes WWW-IR [BAUTIN und SKIENA 2007]
Womit befasst sich die Syntax?
Die syntaktische Ebene
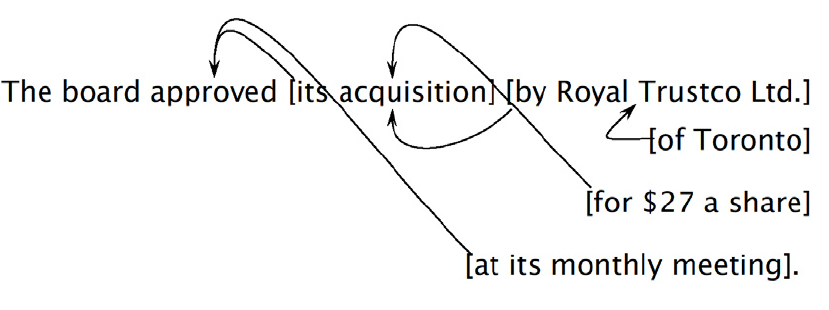
Komplexe Abhängigkeiten und Modifikationsverhältnisse in realen Sätzen
|
|
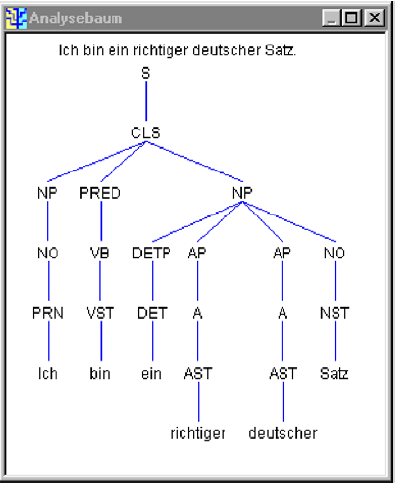
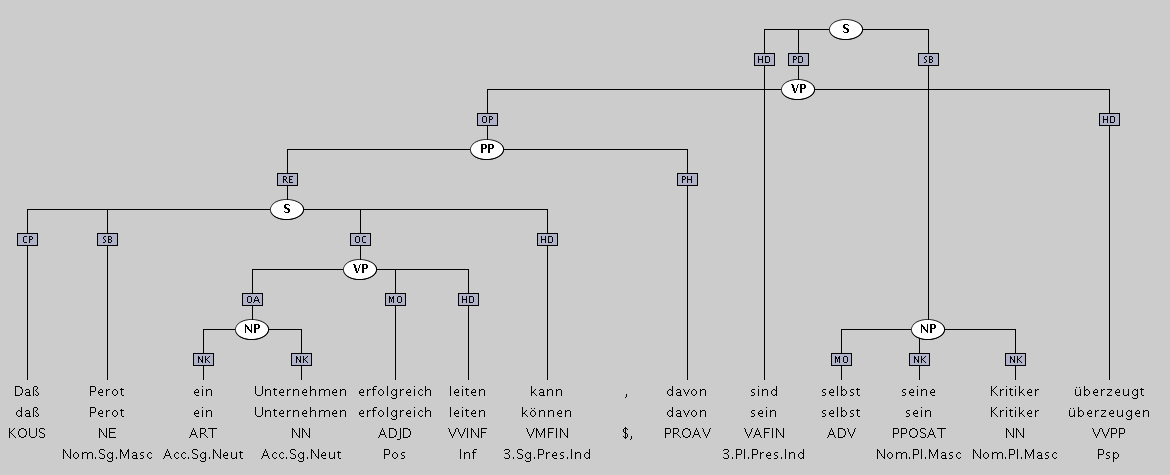
Chunking: Partielle syntaktische Analyse
Definition 1.3.13. Eine partielle syntaktische Analyse (flache Analyse, engl. shallow parsing) berechnet für einen Satz keine vollständige Analyse bezüglich Konstituenz und Dependenz. Gewisse Teilstrukturen bleiben nebengeordnet und in ihrer syntaktischen Funktion unbestimmt .
|
|
Wie kann man die zulässigen Chunks beschreiben?
NC -> ART NN
Viele Sätze sind semantisch und/oder syntaktisch mehrdeutig.
Wahrscheinlichste Lesart berechnen
Beispiel 1.3.14 (Gleiche Information, unterschiedliche Formulierung).
Utilisation de vues aériennes et inventaire complet des dégât
Inventaire des dégât causés par les tempêtes au moyen de vue aériennes
Inventaire des dégâts causés par les tempêtes à l’aide de vue aériennes
Beispiel 1.3.15 (Unterschiedliche Information, ähnliche Formulierung).
design computer vs. computer design
Export von Autos aus Deutschland nach den USA vs.
Export von Autos aus den USA nach Deutschland
Sprache und Bedeutung
Ein Ausweg aus der Mehrdeutigkeit
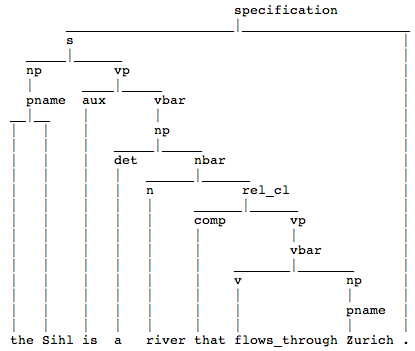
Beispiel 1.3.16 (Kontrolliertes Englisch http://attempto.ifi.uzh.ch).
“Attempto Controlled English (ACE) is a controlled natural language, i.e. a rich subset of standard
English designed to serve as specification and knowledge representation language.”
Syntax und Semantik im ACE-Wiki
|
|
Womit befasst sich die Textlinguistik?
Textlinguistik bei Frage-Antwort-Systemen
Beispiel 1.3.17 (Frage-Beantwortung im LILOG-Projekt (1989-1991)).
Im Palais Nesselrode ist das Hetjensmuseum, das 1909 eröffnet wurde, untergebracht. Es befindet sich
an der Ecke Schulstrasse und Hafengasse. Die Keramiksammlung umfasst zehntausend Objekte. Der
Eintritt der Ausstellung, die von 10 bis 17 Uhr geöffnet ist, beträgt 2 DM. F: Wann ist das
Hetjensmuseum geöffnet?
A: Von 10 Uhr bis 17 Uhr.
F: Ist es um 14 Uhr geöffnet?
A: Ja.
Schwierigkeiten bei der Beantwortung
Forschungsziele heute: Textual Entailment Task
Recognising Textual Entailment Challenge
Wissenschaftliche Wettbewerbe mit systematische Evaluation der textsemantischen Schlussfolgerung
Entscheidungsaufgabe http://pascallin.ecs.soton.ac.uk
Folgt ein Satz aus einem Textstück? Ja oder Nein?
|
|
[ Weiter ] [ Zurück ] [ Zurück (Seitenende) ] [ Seitenbeginn ] [ Überkapitel ] [ Bitte Skript-Fehler melden ]