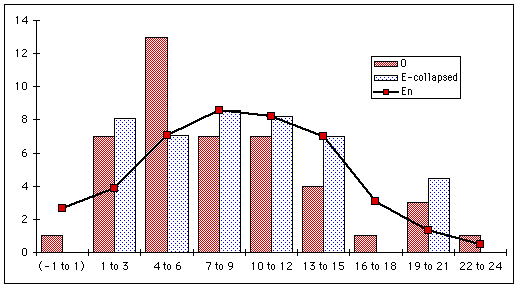
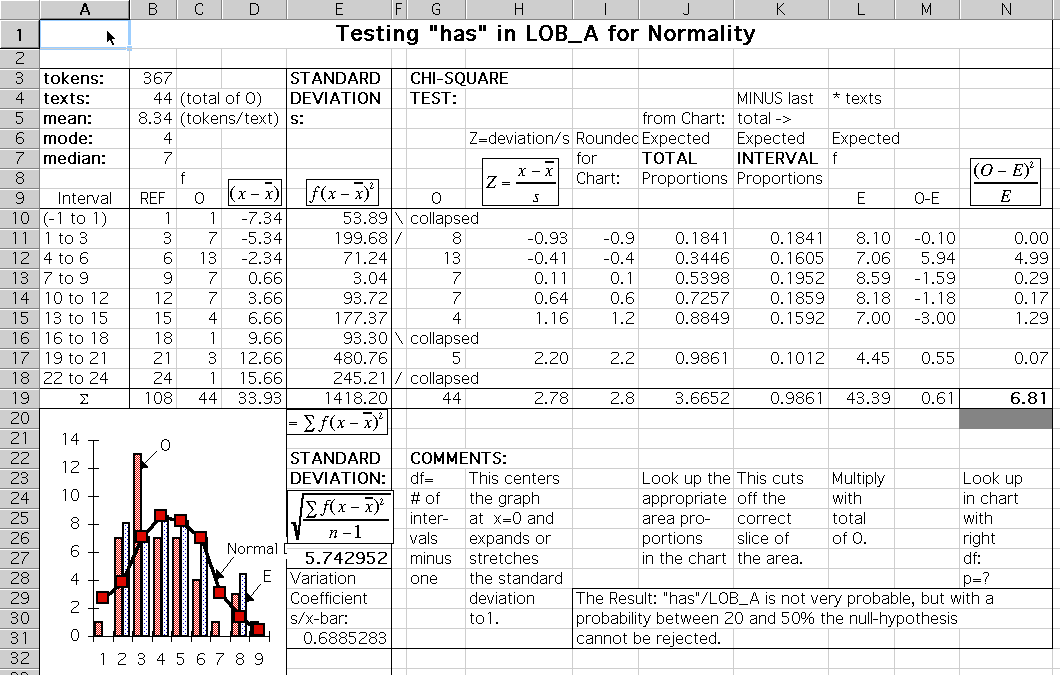
For the expected values E you simply enter the O values of the large corpus as E. However, the corpus should be considerably larger to assure its quality of being a reference. If the reference data is only of similar size as the O data, the contingency-table method is preferrable, since it calculates E values composed of both the reference data and the O data to be tested, while respecting their appropriate sizes.
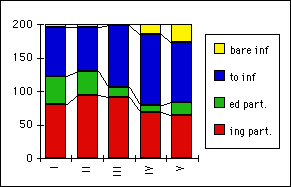
The example uses the distribution of the first 200 non-finite verbs of 5 different texts: